
Classificação versus Regressão
Em aprendizagem supervisionada, as tarefas podem ser divididas em Classificação e em Regressão. Em Classificação, o objetivo é predizer uma classe. Por exemplo, em um sistema de detecção de fake news, deseja-se verificar se um conteúdo é fake ou não; logo, tem-se duas classes. Em uma tarefa diferente, o objetivo pode ser de outra natureza, tal como: prever a quantidade de chuva em determinada região numa data futura; esta é uma tarefa de Regressão.
Estas duas tarefas diferem primordialmente em razão das suas varáveis-alvo: uma é discreta (detecção de fake news) e a outra é contínua (previsão pluviométrica). Assim, quando a variável-alvo pode ser representada por um conjunto finito, a tarefa é dita de Classificação. Por outro lado, diz-se que a tarefa é de Regressão quando a variável-alvo é um valor real (contínuo). Ou seja, na detecção de fake news, tem-se duas classes (fake e não-fake), logo, um conjunto finito de valores. Já na tarefa de previsão pluviométrica, a quantidade de chuva, possivelmente dada em milímetros por metro quadrado, é um valor real, contínuo.
Dados desbalanceados
Dados desbalanceados são, frequentemente, encontrados em aplicações do mundo real e podem impor desafios às máquina de aprendizagem. Pode-se dizer que as classes estão desbalanceadas quando o número de instâncias em uma classe é muito menor do que o número de instâncias numa classe diferente. Na sentença anterior, foi utilizado o conceito de classe, remetendo a definição de dados desbalanceados para tarefas de Classificação. Mas, e para tarefas de Regressão?
Verdade que esta questão de desbalanceamento já foi amplamente discutida em tarefas de Classificação. Porém, vale destacar que em tarefas de Regressão, na qual a variável-alvo é um valor contínuo, dados desbalanceados também podem se apresentar como um obstáculo. Pois, os dados pouco representados podem ser coincidentemente os mais relevantes para a aplicação sob análise. Por exemplo, eventos climáticos extremos ocorrem com menos frequência, mas, erros em sua predição podem ser significantemente custosos.
Em Regressão, calculamos o quão desbalanceado está uma tarefa usando uma função de relevância que separa as instâncias em “normais” e “raras”, com base nos seus valores-alvo. Assim, podemos calcular o nível de desbalanceamento pela razão entre a quantidade de instâncias “raras” e “normais”. Caso tenhamos, bem mais instâncias “normais” do que “raras”, dizemos que a tarefa está desbalanceada.
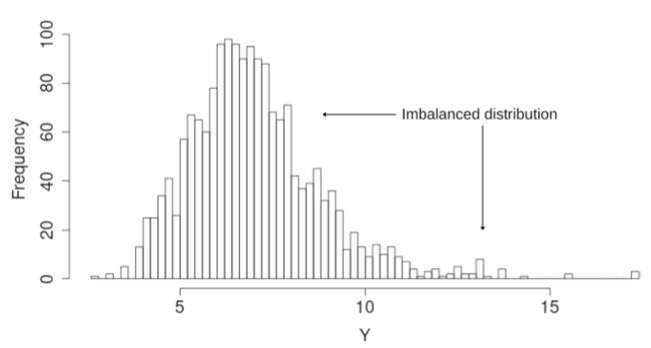
Na figura acima, percebe-se que a quantidade de instâncias com valores de Y (variável-alvo) maiores do que 10 é pouca quando comparada a quantidade de instâncias com valores entre 5 e 8. Logo, boa parte dos valores-alvo é pouco representada e isso dificulta o processo de treinamento das máquinas de aprendizagem.
Algoritmos de balanceamento de dados para Regressão
Uma abordagem bastante usada para lidar com esta questão é o balanceamento dos dados. São vários os possíveis algoritmos na literatura especializada da área. Alguns algoritmos visam gerar instâncias sintéticas que pertençam à classe de instâncias “raras” com o intuito de “engordar” esta classe e, consequentemente, diminuir o desbalanceamento. Em contraste, outras abordagens eliminam algumas instâncias da classe “normal” e, existem, também, algoritmos híbridos que fazem a “engorda” e a eliminação simultaneamente.
Os principais algoritmos de balanceamento de dados para tarefas de regressão foram analisados no artigo listado a seguir. Além da descrição das vantagens e das desvantagens de cada algoritmo, também foram realizados experimentos usando trinta bancos de dados de Regressão de diferentes domínios (desde previsão da qualidade de vinho a incêndios em florestas, passando por tarefas relacionadas à saúde humana).
Juscimara G. Avelino, George D.C. Cavalcanti, Rafael M.O. Cruz. Resampling strategies for imbalanced regression: a survey and empirical analysis. Artificial Intelligence Review, 2024.
As principais contribuições do artigo são:
- Proposição de uma nova taxonomia para tarefas de regressão desbalanceadas levando em consideração o modelo de regressão, a estratégia de aprendizagem e as métricas;
- Revisão das principais estratégias utilizadas para tarefas de regressão desbalanceada;
- Condução de um extenso estudo experimental comparando o desempenho de estratégias de reamostragem e seus efeitos em múltiplos algoritmos de aprendizagem.
Seguem as principais conclusões após a análise dos experimentos:
- A seleção da estratégia de balanceamento pode impactar significativamente os resultados e é melhor usar uma técnica de balanceamento do que não usar nenhuma;
- A escolha da melhor técnica depende da tarefa, do modelo de aprendizagem e da métrica usada. Destaque positivo para a técnica Gaussian Noise, independente da métrica usada;
- Como esperado, os modelos de regressão enfrentaram desafios significativos em tarefas com alto nível de desbalanceamento.
O código-fonte de todas as análises estão publicamente acessíveis no GitHub: https://github.com/JusciAvelino/imbalancedRegression.

Massa professor! Parabéns pela pesquisa.
CurtirCurtir