Um dos pontos que devemos atentar ao treinar uma máquina de aprendizagem é o desbalanceamento entre as classes. Podemos dizer que as classes estão desbalanceadas quando o número de padrões em uma classe é muito menor do que o número de padrões numa classe diferente.

Veja o exemplo na figura acima que mostra duas classes: azul e vermelha. Nesse conjunto, temos 100 padrões da classe azul e 10 da classe vermelha. Logo, a quantidade de padrões na classe azul é 10 vezes maior do que a quantidade de padrões na classe vermelha. O imbalance ratio (IR) é usado para medir esse desbalanceamento, e é calculado como sendo a razão entre o número de padrões na classe majoritária e o número de padrões na classe minoritária. Para esse exemplo, o IR é igual a 10, pois temos uma razão de um para dez (1:10).
Em muitos problemas do mundo real, esse desbalanceamento é bem mais acentuado. Vamos supor um cenário no qual a razão fosse de 1:1000, ou seja, para cada padrão da classe vermelha, temos mil padrões da classe azul. Nesse cenário, caso uma máquina de aprendizagem sempre respondesse “classe azul”, para qualquer padrão fornecido como entrada, essa máquina atingiria uma acurácia (número de acertos dividido pelo número total de padrões avaliados) próxima a cem porcento. Para ser mais preciso, supondo um conjunto com 3003 padrões, sendo 3 da classe vermelha e 3000 da classe azul (para manter a proporção de 1 para 1000), a acurácia seria de 3000/3003, ou seja, 99,9001% de acerto.
Embora essa taxa de acerto, superior a 99,9%, seja bastante promissora, vale salientar que essa máquina de aprendizagem, de fato, não “aprendeu” nada. Ela, de certa forma, foi guiada a minimizar o erro no conjunto de treinamento (com ampla maioria de padrões da classe azul) e, nesse caso, o treinamento pode tê-la levado a desprezar os padrões da classe vermelha.
No exemplo acima, uma máquina conseguiu quase cem porcento de acerto, mesmo sem aprender a tarefa de maneira relevante. Para esses casos, a acurácia não é uma medida interessante, pois é uma medida global, calculada sem fazer distinção entre as classes. Quando avaliamos conjuntos de dados desbalanceados, devemos utilizar medidas que avaliem as classes separadamente, por exemplo: f-score, g-mean e area under the ROC curve.
É fato que várias máquinas de aprendizado podem, de maneira enviesada, priorizar a classe majoritária durante o seu treinamento. Assim, as principais alternativas para lidar com conjuntos de dados, nos quais as classes estejam desbalanceadas são:
- pré-processamento: o objetivo é deixar todas as classes com um número similar de padrões, ou seja, balancear as classes. Técnicas de undersampling (remover padrões da classe majoritária) e/ou de oversampling (adicionar padrões na classe minoritária) são empregadas;
- algoritmo com penalização: os algoritmos de aprendizagem são modificados com o intuito de torná-los sensíveis à questão do desbalanceamento. Assim, durante o processo de treinamento da máquina, o custo ao errar um padrão da classe minoritária é bem maior do que o custo associado a um erro na classe majoritária;
- ensemble: nessa abordagem, técnicas de pré-processamento são usadas em conjunto com sistemas de múltiplos classificadores. Desta forma, ao invés de centralizar o conhecimento em apenas uma máquina de aprendizagem, o conhecimento extraído dos dados de treinamento é dividido em várias máquinas.
Das três alternativas listadas acima, a mais comumente usada é a primeira: pré-processamento. Embora, seja importante destacar a última, ensemble, pois essa tem alcançado resultados superiores quando comparada às demais (artigo).
E para tarefas multi-classe?
A questão fica um pouco mais sutil, quando temos mais de duas classes. Veja o exemplo na figura a seguir.
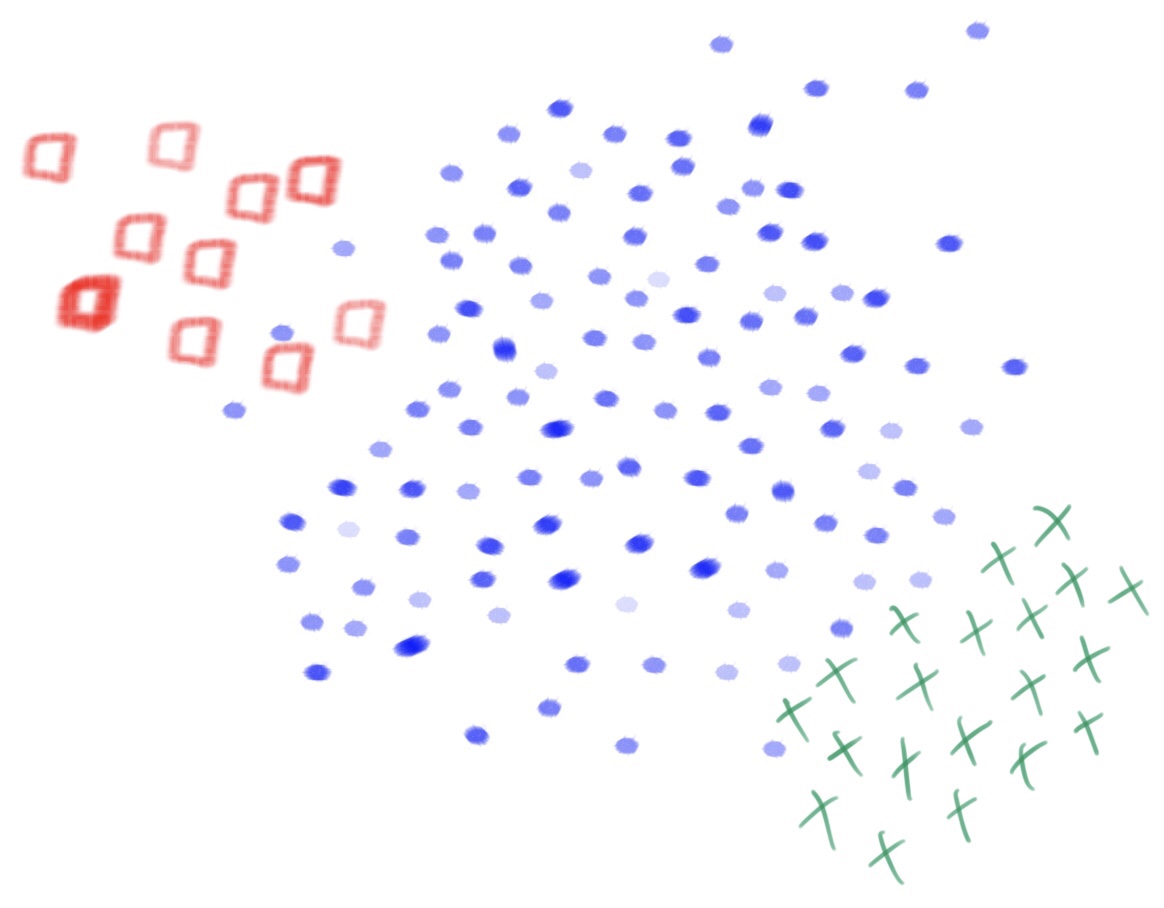
Observando essa imagem, podemos dizer que a classe verde é minoritária em relação à classe azul e majoritária em relação à classe vermelha. Assim, a relação entre as classes já não é tão óbvia quanto em problemas com duas classes. Além disso, o cálculo do IR, conforme descrito anteriormente, não representa uma medida tão confiável. Isso acontece porque diferentes conjuntos de dados podem ter o mesmo IR, desde que, a proporção, entre a quantidade de padrões na classe com mais exemplos e a quantidade de padrões na classe com menos exemplos, seja mantida. Note que, o IR do exemplo com três classes, é o mesmo do exemplo com duas classes: 10; pois, no cálculo do IR, o número de exemplos nas demais classes (que não seja a classe majoritária e a classe minoritária) não é levado em consideração. Mas, existem outras formas de calcular o IR, por exemplo: dividindo o número de exemplos na classe majoritária pela soma das quantidades de padrões de todas as outras classes. Assim, o IR para o problema para três classes ficaria igual a 3,33, ou seja, cem padrões da classe azul dividido por trinta (20 padrões da classe verde mais 10 da classe vermelha).
É relevante destacar, que essa questão do desbalanceamento entre classes, é mais grave quando lidamos com tarefas que dispõem de poucos padrões. Para tarefas, nas quais o número de padrões é extremamente alto para todas as classes, essa questão é minimizada. Ao acessar muitos padrões, podemos construir um conjunto de treinamento balanceado, basta realizar undersampling na classe majoritária.
Além disso, o desbalanceamento, por si só, não representa um problema! Basta que as classes (mesmo que desbalanceadas) estejam bem separadas no espaço de características, consequentemente, a tarefa da máquina de aprendizagem será bem simples. Veja, que no exemplo acima, as classes vermelha e verde, embora desbalanceadas, são linearmente separáveis. Logo, um Perceptron (uma reta) seria suficiente para realizar uma classificação perfeita dos exemplos dessas classes. A dificuldade emerge quando, além de desbalanceadas, as classes se sobrepõem. Observe que as bordas, entre as classes vermelha e azul e entre as classes azul e verde, são mais complexas de serem definidas.