Texto publicado no Jornal do Commercio (JC) em 17/02/2025 (link)
Chatbots, como o ChatGPT, Gemini, entre outros, revolucionaram a forma como lidamos com diversas tarefas relacionadas ao processamento de linguagem natural — tecnologia de inteligência artificial (IA)capaz de interpretar, manipular e compreender a linguagem humana, seja falada ou escrita.
O alicerce atual para essas ferramentas são grandes modelos de linguagens (large language models (LLM), em inglês). Até então, um dos desafios para a construção de LLMs residia no custo para treiná-las. Estima-se que o custo para o treinamento do GPT-4 da OpenAI tenha ultrapassado os 75 milhões de dólares. Logo, o desenvolvimento de tais ferramentas estava fora do alcance da maioria das empresas.
Esse status quo foi colocado à prova com o lançamento do aplicativo de chatbot DeepSeek R1, produto de uma empresa chinesa, especializada em inteligência artificial, fundada em 2023. A DeepSeek afirma que o custo de treinamento de sua ferramenta foi de, aproximadamente, 6 milhões de dólares (menos de 10% do custo do GPT-4). E mais, o DeepSeek obteve desempenho superior em algumas tarefas, tais como matemática e raciocínio, quando comparado ao GPT-4, por exemplo.
Este é mais um curioso caso no qual restrições podem exercer um poder transformador. O aplicativo R1 foi desenvolvido em um momento de sanções de exportação de chips de computadores dos Estados Unidos para China; chips amplamente usados para a produção de programas de inteligência artificial que precisam de muito processamento e que lidam com muitos dados. Logo, os engenheiros de software da DeepSeek propuseram inovações que culminaram em um modelo que necessita de um décimo do poder computacional de um LLM equivalente.
Daí emerge uma novidade: dispomos de um chatbot rápido, mais barato e que ainda apresenta desempenho comparável aos principais concorrentes. Se isso não bastasse, o R1 adota uma tecnologia de pesos aberta, na qual qualquer pessoa pode usar e modificar o programa de computador para atingir seus objetivos.
Vale salientar que a DeepSeek não surgiu por acaso. Emergiu de um plano com metas governamentais chinesas para atingir a liderança mundial em IA. Plano esse norteado por investimentos em formação de especialistas em inteligência artificial, infraestrutura, desenvolvimento industrial e pesquisa científica avançada.
A DeepSeek também se destaca pela descrição detalhada de seus métodos em artigos científicos e pela estratégia de ciência aberta. Mas, ferramentas dessa natureza, seja ChatGPT ou DeepSeek, extraem informações de dados e não são imunes a um potencial viés — seja de gênero, de etnia, de orientação sexual ou outro. Além do mais, tais modelos são tão bons quanto os dados que foram usados para construí-los. Outra preocupação reside na privacidade dos dados. Lembrando que dados são a matéria-prima dessas ferramentas.
Certo é que a liderança das gigantes americanas foi chacoalhada e que muitos outros modelos vão surgir em breve, mais baratos e melhores. A jornada está só no início!


 Esse “poder das multidões” (
Esse “poder das multidões” (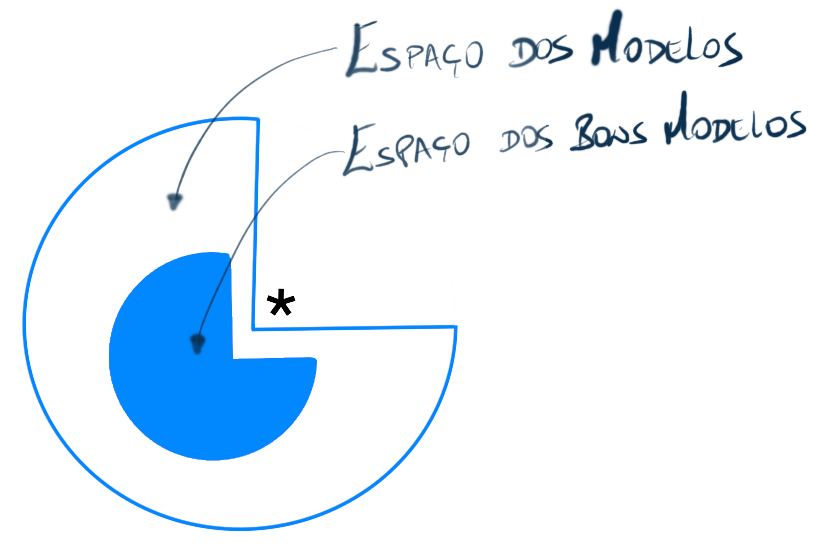 Nela, vê-se que o “esp
Nela, vê-se que o “esp