
Os avanços científicos e tecnológicos em processamento de linguagem natural têm o objetivo de intermediar a comunicação entre computadores e humanos usando seu principal meio de transmissão de informação, de conhecimento e de sentimento: a linguagem natural. A comunicação entre humanos é uma relação social bastante complexa que envolve o uso de diversos recursos, tais como: gestos e símbolos. Mas, dentre todos os meios, a palavra merece uma atenção especial, por sua abrangência e alcance.
A confluência entre palavras e sistemas de aprendizagem de máquina mostra um caminho para a produção de aplicações que agregam valor a diversas tarefas: tradução, detecção de fake news, deteção de hate speech, categorização de documentos, análise de sentimentos e de emoções, entre outras. Um pilar fundamental para o sucesso da automatização de tais aplicações reside na representação dessas palavras de uma forma que facilite a tarefa das máquinas de aprendizagem. Essa tal representação deve preservar o significado das palavras.
O WordNet é um dicionário de sinônimos de palavras em inglês. Além dos sinônimos, o WordNet armazena, para cada palavra, um conjunto de relações do tipo “é um”. Por exemplo: para a palavra morcego, as relações “é um” animal, “é um” mamífero, entre outras, podem ser recuperadas. Assim, o WordNet é uma alternativa para representar palavras, porém, possui algumas limitações. Uma delas refere-se a incompletude, ou seja, faltam sinônimos de várias palavras, especialmente, de palavras mais novas. Ao se analisar textos, algumas palavras aparecem regularmente próximas entre si, enquanto outras, raramente, aparecem juntas. Para exemplificar: as palavras “tubarão” e “baleia” ocorrem juntas com mais frequência do que as palavras “tubarão” e “deserto”. Logo, uma informação importante diz respeito à similaridade entre palavras, e isso, o WordNet também não oferece.
One-hot encoding
Até 2012, boa parte das aplicações representavam palavras usando uma codificação ortogonal. Para ilustrar, um corpus composto por seis palavras: tubarão, baleia, deserto, golfinho, mamífero e peixe, seria representado pelos vetores binários:

Essa forma de representar, também conhecida como one-hot encoding, traz consigo algumas questões. Em geral, um corpus (conjunto de textos) possui mais do que seis palavras. Dado que o tamanho do vetor, que representa cada palavra, é igual ao número de palavras no corpus, esse vetor terá, facilmente, o tamanho de algumas centenas de milhares de posições. Logo, são vetores grandes e esparsos (cada vetor possui apenas um valor “1” e vários “0”s).
Outro fator negativo ao empregar o one-hot encoding está relacionado à similaridade entre as palavras. Nessa representação, a distância entre quaisquer duas palavras é a mesma, pois cada palavra é um vetor perpendicular a todos os outros, logo, o produto interno entre dois vetores é igual a zero. Desta forma, a distância entre as palavras “baleia” e “golfinho” e as palavras “baleia” e “deserto” é a mesma. Nenhuma relação entre as palavras é estabelecida, e isso fere o objetivo de adicionar semântica ao processo, pois sabemos que as palavras “baleia” e “golfinho” aparecem mais frequentemente juntas do que as palavras “baleia” e “deserto”.
Word vectors
Tendo em vista que a relação entre as palavras é importante, pois é uma forma de adicionar semântica ao processo, alternativas foram desenvolvidas para incluir essa informação de contexto no vetor que representada cada palavra. Desde 2013, uma forma de mapear palavras em vetores com valores reais, estabeleceu-se como o estado da arte da área: word vectors (word embedding).
Ao contrário do one-hot enconding, no qual um vetor perpendicular às demais palavras é atribuído a cada palavra, os word vectors são aprendidos usando uma rede neural artificial. Esse processo de aprendizagem dos vetores leva em consideração o fato de que palavras que ocorrem em contextos similares possuem semânticas, também, similares. Dito de outra forma, se a palavra “peixe” aparece próxima da palavra “tubarão” mais frequentemente do que a palavra “mamífero”, é esperado que as palavras “peixe” e “tubarão” sejam mais “parecidas”, semanticamente, do que as palavras “peixe” e “mamífero”. Assim, deseja-se construir vetores que representem as palavras de forma que a distância entre “peixe” e “tubarão” seja menor do que a distância entre “peixe” e “mamífero”.
A figura a seguir mostra exemplos de word vectors nos quais é possível observar que as distâncias entre as palavras não é a mesma e que algumas relações semânticas, semelhantes às descritas no parágrafo anterior, são preservadas. Nota: cada uma das palavras dessa figura era formada originalmente por um vetor de cem valores e, para fins de visualização, a dimensionalidade foi reduzido para duas usando a análise dos componentes principais. Logo, muita informação foi perdida nesse processo de redução para uma representação 2D.

Mas, como embutir tal semântica nos vetores que representam as palavras, sabendo que tais vetores são compostos por números reais? Para ilustrar a intuição dessa construção dos vetores, veja o exemplo a seguir que mostra a frase “Focas, orcas, golfinhos e baleias são mamíferos que vivem nos mares”. Nesse exemplo, o elemento “central” é dado pela palavra “baleia” e os elementos de “contexto” estão destacados em verde. Esse processo é chamado de janelamento e, para essa ilustração, foi usado uma janela de tamanho cinco. De maneira iterativa, essa janela percorre a frase, colocando outras palavras como o elemento “central”.
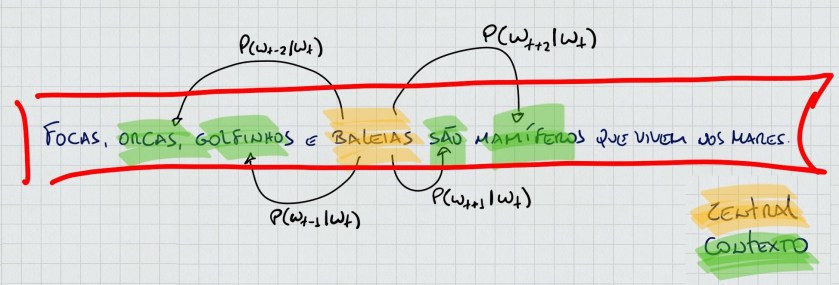
Os valores que compõem o vetor da palavra “central” são atualizados de maneira que consigam predizer quais palavras formam o “contexto”. Na figura, wt representa a palavra central “baleia” e P(wt+2|wt) é a probabilidade de predizer a palavra “mamífero” (wt+2) dada a palavra “baleia” (wt). Desta forma, ao apresentar várias e várias janelas à máquina de aprendizagem, o modelo consegue aprender o contexto de palavras estimando a probabilidade de uma palavra no “contexto” ser predita pela palavra “central”. E, ao fim, esse processo “magicamente” embute o significado das palavras nos valores dos vetores. Para mais detalhes sobre o funcionamento do modelo, veja o artigo que propõe o Word2vec. Esse é o modelo seminal que usa uma rede neural para representar as palavras seguindo a intuição descrita acima.
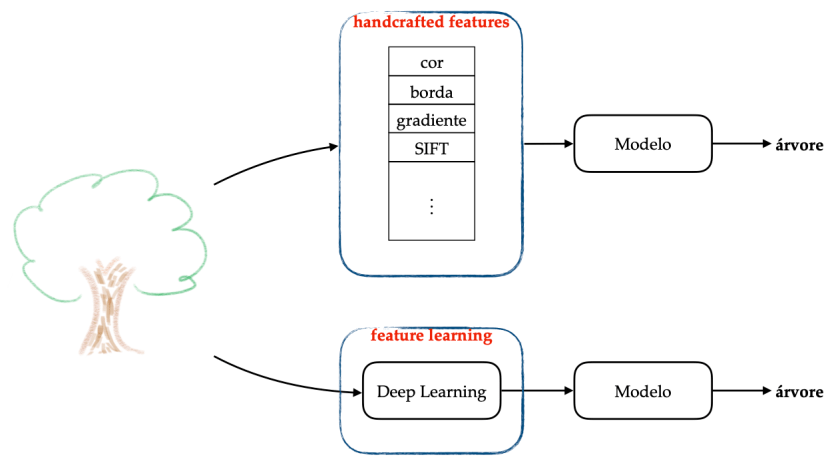 Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links:
Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 