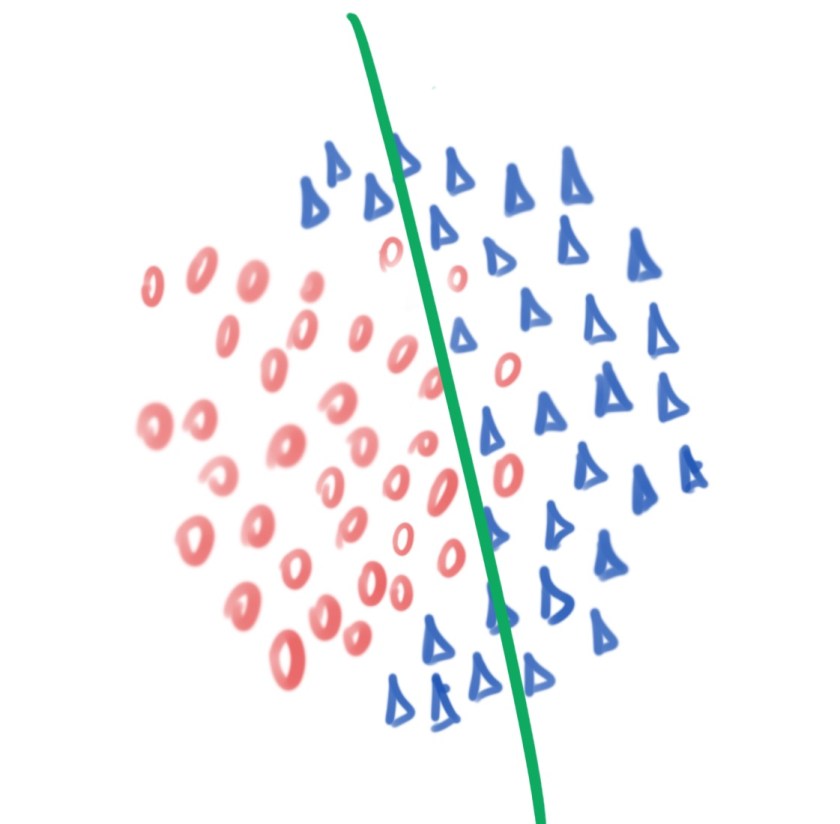
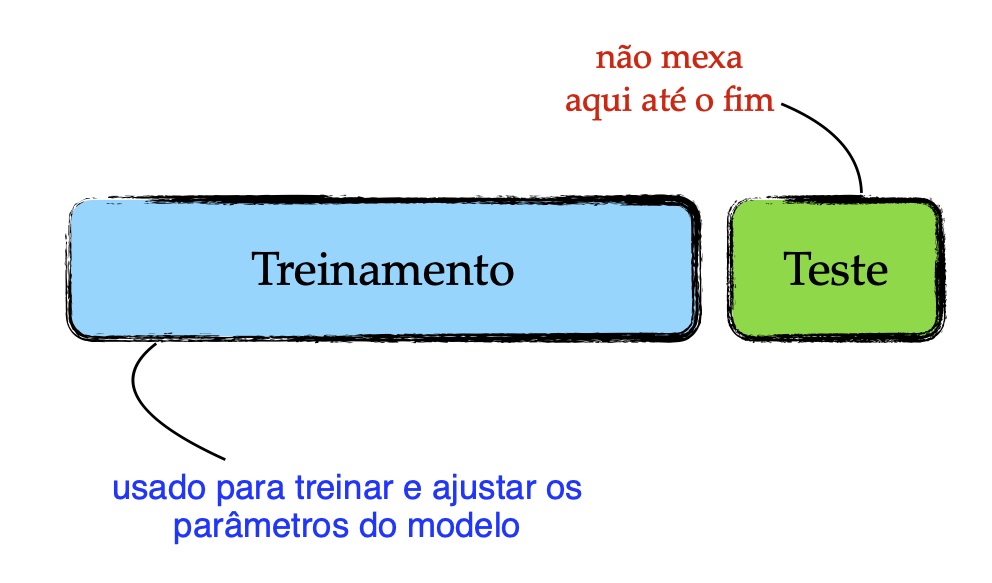
Ao treinar uma máquina de aprendizagem, muitos desafios espreitam o horizonte, entre eles: overfitting. Uma das alternativas para minimizar overfitting é escolher a máquina correta para a tarefa que se deseja resolver. Por exemplo: se tivermos poucos dados disponíveis, uma rede neural artificial pode não ser a melhor escolha; embora existam estratégias para gerar dados artificiais e aumentar a quantidade de dados de treinamento, tais como oversampling e data augmentation. Uma escolha mais apropriada seria um algoritmo de instante-based learning, e.g., k-nearest neighbor.
Escolher o melhor algoritmo de aprendizagem, por tarefa, é uma problema em busca de solução. Muitas abordagens que se valem de meta-learning já foram propostas, mas ainda existe muito terreno a percorrer nesse campo. Essa é uma pesquisa bem interessante e motivada, também, por um teorema de nome engraçado, mas, extremamente importante para a área, chamado de no free lunch theorem. Esse teorema nos indica que não existe uma máquina de aprendizagem que seja a melhor para todas as tarefas. Ou seja, cada tarefa tem suas peculiaridades que devem ser melhor resolvidas por máquinas que tenham características distintas. Nota: um teorema é uma afirmação provada como verdadeira; logo, essa difere de uma mera opinião.
Consequentemente, é responsabilidade do especialista em aprendizagem a escolha da melhor máquina para resolver uma nova tarefa. Mas, existe outra alternativa…
Se para cada tarefa, uma máquina deve ser escolhida, por que não unir esforços e juntar várias máquinas para resolver essa tal tarefa? Vox Populi, Vox Dei.  Esse “poder das multidões” (wisdom of the crowd) é a premissa da área de Combinação de Classificadores (ensemble learning) que possui vários nomes, tais como: sistemas de múltiplos classificadores e máquinas de comitê. Esses sistemas combinam máquinas com o intuito de melhorar a precisão geral do sistema, fundamentando-se no argumento de que a junção das opiniões de um grupo de indivíduos é melhor do que a opinião de apenas um indivíduo.
Esse “poder das multidões” (wisdom of the crowd) é a premissa da área de Combinação de Classificadores (ensemble learning) que possui vários nomes, tais como: sistemas de múltiplos classificadores e máquinas de comitê. Esses sistemas combinam máquinas com o intuito de melhorar a precisão geral do sistema, fundamentando-se no argumento de que a junção das opiniões de um grupo de indivíduos é melhor do que a opinião de apenas um indivíduo.
Em um experimento, no início do século vinte, Sir Francis Galton — o mesmo que desenvolveu um método eficiente para classificação de impressões digitais — combinou a resposta de 787 pessoas que estimaram o peso de um boi morto e vestido. Ao calcular a média das respostas de todos os participantes, Galton observou que o erro foi menor do que um porcento (link). Ao invés de combinar as respostas de todos, Galton poderia ter escolhido o indivíduo mais competente para estimar o peso. Entretanto, essa escolha não seria uma tarefa trivial, da mesma forma que, escolher a melhor máquina de aprendizagem, por tarefa, não é uma tarefa simples. Assim, ao combinar todas as respostas, a probabilidade de escolher um indivíduo incompetente foi minimizada.
É inútil combinar máquinas que tenham o mesmo comportamento, ou seja, máquinas que acertem e errem as mesmas instâncias. Assim, ao juntar várias máquinas em um pool, é esperado que elas tenham um excelente desempenho em partes diferentes do espaço de características. Em outras palavras, é fundamental que as máquinas sejam diversas entre si. Existem várias maneiras de se obter diversidade, entre elas: usar diferentes algoritmos de aprendizagem e usar dados diferentes para treinar cada uma das máquinas.
Razões para combinar máquinas
Os aspectos que fortalecem o uso de estratégias de combinação de classificadores podem ser aglutinados em: estatístico, computacional e representacional. A figura ao lado é usada para explicar esses três aspectos.  Nela, vê-se que o “espaço dos bons modelos”, para uma dada tarefa, é um subconjunto do “espaço dos modelos”. Esses modelos são máquinas de aprendizagem, de classificação ou de regressão, que foram treinadas com dados de uma tarefa específica. Além disso, o asteriscos (∗) representa o classificar ideal, os círculos (•) são os classificadores individuais e o triângulo (Δ) representa a combinação dos classificadores (ensemble). Objetiva-se obter um modelo o mais próximo possível do modelo ideal (∗). Nota: essa figura foi adaptada da figura 3.2 do livro da Kuncheva, 2014.
Nela, vê-se que o “espaço dos bons modelos”, para uma dada tarefa, é um subconjunto do “espaço dos modelos”. Esses modelos são máquinas de aprendizagem, de classificação ou de regressão, que foram treinadas com dados de uma tarefa específica. Além disso, o asteriscos (∗) representa o classificar ideal, os círculos (•) são os classificadores individuais e o triângulo (Δ) representa a combinação dos classificadores (ensemble). Objetiva-se obter um modelo o mais próximo possível do modelo ideal (∗). Nota: essa figura foi adaptada da figura 3.2 do livro da Kuncheva, 2014.

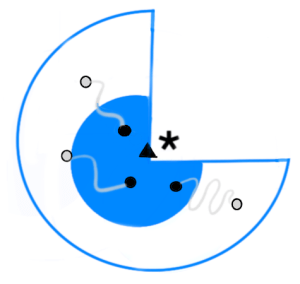

Estatístico
Na figura que mostra o aspecto Estatístico, percebe-se que o modelo combinado (Δ) está bem mais próximo do modelo ideal (∗) do que a maioria dos modelos individuais (•). Vale salientar que o modelo combinado não é o melhor, pois existe pelo menos um modelo (•) que está mais próximo do modelo ideal do que o modelo combinado. Entretanto, por melhor que seja o seu procedimento experimental, a incerteza relacionada à precisão do modelo, aferida durante o treinamento, pode levar a escolha de um modelo inadequado. Assim, ao combinar os modelos, minimiza-se a chance de selecionar um modelo ruim.
Computacional
Durante o treinamento, um modelo é levado do “espaço dos modelos” para o “espaço dos bons modelos” — conforme mostrado pelas curvas em cinza na figura do aspecto Computacional. Cada um desses modelos (•) deve se posicionar em um mínimo local diferente da superfície de erro. Logo, a combinação desses modelos diversos gerará um modelo mais próximo do modelo ideal.
Representacional
Suponha que todos os modelos individuais (•) sejam lineares e que a tarefa, que se deseja resolver, seja não-linearmente separável. Logo, nenhum modelo, cuja representação é linear, será capaz de modelar essa tarefa. Por outro lado, ao combinar modelos lineares, regiões não-lineares podem ser modeladas. Assim, na figura que mostra o aspecto Representacional, percebe-se que o modelo combinado (Δ) está fora do “espaço dos modelos”, pois todos os modelo desse espaço são lineares e o alvo é um modelo não-linear que pode ser alcançado combinando modelos lineares. De maneira geral, regiões complexas de bordas entre classes podem ser modeladas usando modelos simples.
No próximo post, arquiteturas de combinação de classificadores — estática e dinâmica — serão discutidas.