Crowdfunding, ou financiamento coletivo, é uma maneira de conseguir recursos para alavancar um projeto. Para tanto, um indivíduo ou uma startup apresenta sua ideia em plataformas online com o intuito de conseguir uma quantia específica de dinheiro para colocar seu projeto em curso. Tais projetos são financiados, em geral, por um grande grupo de pessoas que acreditam no projeto e que pode se beneficiar, por exemplo, com cotas do empreendimento.
Algumas campanhas de crowdfunding são exitosas; enquanto outras não conseguem angariar a quantidade de recurso suficientes para iniciar o projeto e, assim, naufragam. Separar, o quanto antes, campanhas de sucesso das que irão fracassar implica em redução de custos e de frustrações de parte a parte.
No artigo a seguir, investigamos diversas abordagens de aprendizagem de máquina para a predição de sucesso em campanhas de crowdfunding.
George D.C. Cavalcanti, Wesley Mendes-Da-Silva, Israel J. dos Santos Felipe, Leonardo A. Santos. Recent advances in applications of machine learning in reward crowdfunding success forecasting. Neural Computing & Applications, 2024.

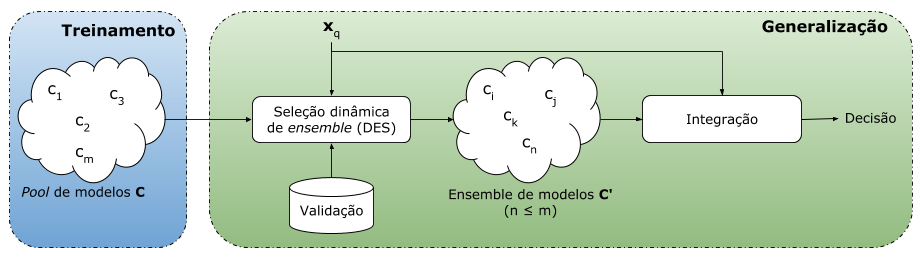
Foram avaliados 15 algoritmos de aprendizagem de máquina, entre eles, algoritmos tradicionais (MLP, SVM, …), algoritmos de combinação estática (RandomForest, AdaBoost, XGBoost, …) e algoritmos de combinação dinâmica de classificadores (Meta-DES, KNORAE, …), usando três métricas: acurácia, área sob curva ROC e F-score, e um total de 4.193 campanhas. Destaque para o Meta-DES que obteve o melhor resultado global. Este método usa meta-aprendizagem para selecionar dinamicamente os melhores classificadores por campanha de crowdfunding em avaliação. Em outras palavras, o Meta-DES usa classificadores diferentes para avaliar campanhas diferentes e esta escolha é realizada on-the-fly, ou seja, em produção.
Boa parte da discussão do artigo é voltada para explicar (eXplainable AI) os motivos que levaram a máquina de aprendizagem a indicar que uma determinada campanha seria de sucesso ou não. Para tanto, computamos os Shapley values visando enxergar o conteúdo da black-box das máquinas.

De maneira global, as variáveis mais importantes para a predição foram: o número de pledges, o valor total esperado na campanha, entre outras, conforme mostrado no gráfico acima.
Dentre as variáveis usadas para representar uma campanha, duas delas têm o objetivo de capturar o sentimento do mercado no dia do lançamento da campanha de crowdfunding, são elas: social media net sentiment (SMNS) e mainstream media net sentiment (MMNS). Esse sentimento foi extraído do Twitter e do jornal “O Estado de São Paulo” usando técnicas de processamento de linguagem natural. Embora tenhamos usado apenas duas fontes de informações online, vale destacar que essas variáveis foram relevantes para as decisões das máquinas.
Destaco que este trabalho foi realizado com 4.193 campanhas do mundo real. Um esforço multidisciplinar como este requer a adição de diferentes competências complementares. Agradeço aos co-autores: Wesley (Professor de Finanças/FGV-SP), Israel (Professor de Finanças/UFRN) e Leonardo (Senior Machine Learning Engineer/Nubank).
O código-fonte e mais detalhes sobre a análise experimental estão disponíveis no GitHub: https://github.com/las33/Crowdfunding.