A matéria a seguir foi publicada no Jornal do Commercio (JC) em 05/03/2026 (link).
Ingressar em uma universidade de topo é mais do que garantir um caminho para um diploma admirável, é o resultado de transformar esforço e disciplina em hábito. Para o estudante com propósito e que consegue definir sua prioridade, a materialização desse sonho representa uma oportunidade para adentrar em um universo no qual o ponteiro da bússola aponta para a excelência.
Escolher uma faculdade é uma decisão multifatorial que agrega estratégia de carreira com estilo de vida. Logo, o estudante, à luz da sua vocação, é levado a refletir sobre vários fatores para balizar esta escolha. Dentre os fatores mais relevantes, alguns se destacam e estão normalmente em pauta, tais como: prestígio da instituição e do curso, oportunidades no mercado de trabalho, custo para se manter no curso, logística, além da infraestrutura proporcionada pela instituição.
O Centro de Informática (CIn) da UFPE é reconhecido como um dos principais pólos de inovação e de excelência acadêmica em computação da América Latina, destacando-se por um ambiente que congrega pesquisa de alto nível e conexão com a indústria. Neste ano, os quatro cursos de graduação oferecidos pelo CIn (Sistemas de Informação, Ciência da Computação, Engenharia da Computação e Inteligência Artificial) ficaram entre os cinco cursos da UFPE com maiores notas de corte para ingresso por ampla concorrência do Sistema de Seleção Unificada (SiSU). O quarto colocado foi o curso de Medicina. O CIn lidera as notas do SiSU pelo pelo terceiro ano consecutivo na UFPE e esse resultado reflete a percepção da sociedade em relação ao que o CIn é capaz de proporcionar não apenas do ponto de vista técnico, mas também da relação com o mercado de trabalho.
Com o intuito de proporcionar uma formação mais ampla, o CIn tem continuamente dado mais protagonismo aos estudantes. Iniciativas como o CIn OpenDay, que abre as instalações do centro para a sociedade, visitas regulares de alunos do ensino médio, ligas acadêmicas, equipes de robótica, empresa júnior, maratona de programação, entre outras, quebram paradigmas, rompem os muros da academia conectando-a à sociedade e promovem excelentes oportunidades de aprendizagem para os nossos alunos.
É notória a abrangência do real impacto da computação nas diversas áreas do conhecimento (saúde, humanas e exatas) nos últimos anos e, em particular, mais recentemente, da Inteligência Artificial (IA). Aliada à excelência do CIn e ao aquecimento do mercado de trabalho na área de informática, tais fatores certamente contribuem para a alta concorrência dos cursos de graduação e são impulsionadores para que todos os que compõem o CIn continuem trabalhando com o intuito de formar profissionais extremamente qualificados, capazes de aprender continuamente, sem jamais esquecer preceitos éticos, fundamentais para os graduados que vão assumir tarefas desafiadoras.
Embora tenham sido 14 anos lecionando a disciplina de Metodologia na graduação em Engenharia da Computação do CIn-UFPE, não posso dizer que foram “longos anos”; passou rápido demais.
Inicialmente, não tinha a intenção de ficar na mesma disciplina por tantos anos. Mas, fui me afeiçoando gradativamente pela arte, em especial, de conduzir os alunos da graduação nos meandros da escrita científica. Um desafio que se mostrou prazeroso, particularmente, ao testemunhar os caminhos percorridos pelos egressos e ter a oportunidade de conversar com eles.
Durante as aulas, desde o início, lá em 2012, aproveitava o ensejo para contar um pouco sobre a vida acadêmica. Discussões sobre o que é um trabalho de conclusão de curso, um mestrado, um doutorado, um pós-doutorado, e, também, sobre as atividades (papéis) de um professor universitário. Levar esse entendimento aos alunos de gradução contribui para o despertar da nova geração de cientistas, além de colocar um pouco de luz nesta cena que ainda respira informações desencontradas. Ademais, como escolher um caminho sem um mínimo de discernimento das competências necessárias para trilhá-lo?
As discussões descritas no parágrafo anterior despertavam, como um reflexo automático, questões sobre as diferenças/contrapontos/(des)vantagens em relação ao mercado de trabalho fora da academia. Logo, o debate ficava ainda mais rico! Assim, investia esforços com intuito de fornecer subsídios para que eles, os alunos, conseguissem avanços no poder de decisão para um planejamento mais consciente das possibilidades que estão por trilhar.
Revisão da literatura, integridade científica, plágio, o método científico e as bases científicas da pesquisa, o que é e como fazer ciência, persuasão, o poder de uma palavra, estruturação de um parágrafo, de uma seção, de um documento, apresentações oral e pôster, entre outros importantes tópicos tiveram espaço garantido nas aulas de Metodó (abreviatura carinhosamente cunhada pelos alunos).
Foram quase 30 turmas e mais de 730 alunos. Vários engenheiros que hoje exercem suas atividades em diferentes empreendimentos (próprios ou não), alguns mestres, outros doutores. Independente do caminho, todos carregam consigo o poder de melhor expressar-se claramente, de maneira concisa e sem ambiguidade. Tríade (clareza, concisão e não-ambiguidade) que repetia a exaustão nas aulas.
Aprendizado contínuo é uma obrigação para conosco que devemos cativar com carinho. Despeço-me da disciplina, mas a Metodologia e a Escrita Científica continuam comigo. Fazem parte do meu dia-a-dia. E, indubitavelmente, tornei-me um professor/cientista melhor após estes 14 anos, por causa de (e para) vocês, meus alunos.
Ao fechar ciclos, abrimos espaços para que outros sejam iniciados!
A matéria a seguir foi publicada no Jornal do Commercio (JC) em 11/08/2025 (link).
O desbravar de caminhos para alcançar inteligência além do ser humano remonta a um passado distante dos tempos modernos. Na mitologia grega, Talos, um autômato gigante de bronze, foi concebido por um deus para proteger a ilha de Creta. Talos é provavelmente a primeira máquina inteligente documentada.
Da Grécia antiga para os dias atuais, a Inteligência Artificial (IA) deixou de ser um assunto apenas relacionado à ficção científica para permear nosso cotidiano. Ao fazer uma busca no Google, somos auxiliados por algoritmos que usam IA. Recomendações de filmes, de livros ou de músicas, nas mais diferentes plataformas, são trabalhos realizados por IA. O acesso ao celular ou aos caixas eletrônicos de bancos usando a impressão digital, a face ou a palma da mão, também é uma tarefa desempenhada por IA. A lista é longa e inclui jogos, redes sociais, sistemas de saúde e financeiro, propaganda, transporte, compras online, só para dar alguns exemplos. Ou seja, artefatos que usam IA já permeiam nosso cotidiano faz algum tempo e, em muitos casos, não estamos cientes de que existe uma IA por trás do processo.
A percepção do público sobre IA vem mudando ao longo do tempo. Embora seja unânime seu poder transformador na sociedade, alguns enxergam um imenso potencial positivo, já outros veem o copo meio vazio. Interagir com um computador super-avançado, como o HAL 9000, do filme “2001: uma Odisseia no Espaço”, despertava o imaginário popular e, esta realidade, começou a se materializar com o advento de assistentes virtuais como Siri, Cortana e Alexa.
Porém, a visão geral do que é IA começou a se modificar de maneira mais evidente ao final de 2022, com o lançamento do ChatGPT. Agora dispomos de robôs de conversação capazes de realizar diferentes tarefas que, no passado, eram atribuídas apenas a humanos, tais como: resolução de problemas, resumo de documentos, escrita de programas de computador e de cartas, análise de dados e criação de imagens e de vídeos. Tudo isso como se estivéssemos conversando, batendo um papo, com um amigo. Logo, esta forma simples de nos comunicarmos com esses robôs gera uma maior visibilidade da existência de IA, além de aproximar essa realidade da sociedade de forma mais ampla. Esta novidade provoca diferentes sensações e é motivo de debate não apenas entre especialistas, mas por boa parte da sociedade.
Depois do ChatGPT, ferramentas similares surgiram: Gemini e Deep Seek, entre outras. Esta diversificação de ferramentas amplia as possibilidades de uso e, por consequência, expande a percepção de suas capacidades. Tais ferramentas têm o propósito de processar linguagem natural, ou seja, dispõe de capacidade de “entender” um comando, seja de texto ou de voz, e de produzir uma resposta. Muitos setores da sociedade, empresas públicas ou privadas, já se beneficiam de tais ferramentas e a tendência é de maior e melhor adesão.
Mas, vale a ressalva de que IA não é apenas um robô de conversação ou um grande modelo de linguagem (LLM, do inglês). Vai muito além! É importante estarmos cientes disso, pois só assim podemos aprofundar a discussão sobre o impacto dessas tecnologias em nossas vidas; pois existem vários aspectos éticos e legais envolvidos. Munidos de tal discernimento, podemos avançar no uso e na construção de ferramentas e de processo educacionais que nos auxiliem a extrair o que de melhor essas novas tecnologias têm a nos oferecer.
No início de maio/2025, iniciou-se o curso de graduação em Inteligência Artificial do CIn-UFPE. A matéria a seguir foi publicada no Jornal do Commercio (JC) em 19/05/2025 (link).
Inovações no campo da Inteligência Artificial (IA) continuam a moldar a forma como construímos a nossa sociedade. A IA é cada vez mais mencionada e discutida, tanto no ambiente profissional quanto em momentos de lazer. Em outras palavras, a IA permeia o nosso cotidiano, independente se estamos cientes ou não de sua existência.
A Inteligência Artificial é um ramo da Ciência da Computação que tem o objetivo de construir máquinas capazes de realizar tarefas que tradicionalmente requerem inteligência humana, tais como raciocinar, aprender e agir. Como exemplos, temos acesso a diversas aplicações que habilitam os computadores a manipular imagens e vídeos, a ouvir comandos de voz e a respondê-los, a gerar, resumir e traduzir textos, a analisar e extrair informações de grandes quantidades de dados de maneira automática. Para que esta “mágica” ocorra, existem pessoas por trás dos bastidores escrevendo programas de computador.
Diante da franca expansão da área IA, os atuais cursos de computação não comportam mais a diversidade de conhecimento necessária para termos especialistas nesta emergente área. Daí, urge a necessidade de um novo curso com uma maior carga horária focada nas tecnologias que envolvem os domínios de ferramentas e de métodos de IA.
Todas essas aplicações e tecnologias de visão computacional, de processamento de linguagem natural e de ciência de dados fazem parte da grade curricular do novo curso. Os egressos do curso terão conhecimento sobre os fundamentos da IA, como ela funciona, como usá-la e quais seus riscos. Além disso, formaremos profissionais capazes de desenvolver as mais diferentes ferramentas e tecnologias relacionadas à IA, e que conseguem não só entender como essas ferramentas funcionam, mas também, como desenvolvê-las de maneira ética e segura.
IA é o curso de graduação caçula do Centro de Informática (CIn) da UFPE que já conta com os cursos de Ciência da Computação, de Engenharia da Computação e de Sistemas de Informação. O dia-a-dia dos alunos será ainda mais rico com a integração entre os quatro cursos que têm a computação como base, além do convívio com alunos de mestrado, de doutorado e de especializações, e várias outras atividades proporcionadas pelo CIn-UFPE aos seus alunos.
Ciente de que as inovações em IA evoluem rapidamente, o bacharelado em IA possui nove semestres recheados com um conteúdo atual, avançado e flexível que permitirá a especialização dos alunos nas mais diversas áreas relacionadas à IA. O curso de graduação em Inteligência Artificial nasce olhando para o futuro, com o objetivo de formar profissionais capacitados não só para lidar com as tecnologias atuais, mas, principalmente, formar profissionais preparados para o alvorecer das mudanças que constantemente nos avizinha.
George Darmiton da Cunha Cavalcanti Coordenador do Bacharelado em Inteligência Artificial Membro da Academia Pernambucana de Ciências Professor Titular do CIn-UFPE
Texto publicado no Jornal do Commercio (JC) em 17/02/2025 (link)
Chatbots, como o ChatGPT, Gemini, entre outros, revolucionaram a forma como lidamos com diversas tarefas relacionadas ao processamento de linguagem natural — tecnologia de inteligência artificial (IA)capaz de interpretar, manipular e compreender a linguagem humana, seja falada ou escrita.
O alicerce atual para essas ferramentas são grandes modelos de linguagens (large language models (LLM), em inglês). Até então, um dos desafios para a construção de LLMs residia no custo para treiná-las. Estima-se que o custo para o treinamento do GPT-4 da OpenAI tenha ultrapassado os 75 milhões de dólares. Logo, o desenvolvimento de tais ferramentas estava fora do alcance da maioria das empresas.
Esse status quo foi colocado à prova com o lançamento do aplicativo de chatbot DeepSeek R1, produto de uma empresa chinesa, especializada em inteligência artificial, fundada em 2023. A DeepSeek afirma que o custo de treinamento de sua ferramenta foi de, aproximadamente, 6 milhões de dólares (menos de 10% do custo do GPT-4). E mais, o DeepSeek obteve desempenho superior em algumas tarefas, tais como matemática e raciocínio, quando comparado ao GPT-4, por exemplo.
Este é mais um curioso caso no qual restrições podem exercer um poder transformador. O aplicativo R1 foi desenvolvido em um momento de sanções de exportação de chips de computadores dos Estados Unidos para China; chips amplamente usados para a produção de programas de inteligência artificial que precisam de muito processamento e que lidam com muitos dados. Logo, os engenheiros de software da DeepSeek propuseram inovações que culminaram em um modelo que necessita de um décimo do poder computacional de um LLM equivalente.
Daí emerge uma novidade: dispomos de um chatbot rápido, mais barato e que ainda apresenta desempenho comparável aos principais concorrentes. Se isso não bastasse, o R1 adota uma tecnologia de pesos aberta, na qual qualquer pessoa pode usar e modificar o programa de computador para atingir seus objetivos.
Vale salientar que a DeepSeek não surgiu por acaso. Emergiu de um plano com metas governamentais chinesas para atingir a liderança mundial em IA. Plano esse norteado por investimentos em formação de especialistas em inteligência artificial, infraestrutura, desenvolvimento industrial e pesquisa científica avançada.
A DeepSeek também se destaca pela descrição detalhada de seus métodos em artigos científicos e pela estratégia de ciência aberta. Mas, ferramentas dessa natureza, seja ChatGPT ou DeepSeek, extraem informações de dados e não são imunes a um potencial viés — seja de gênero, de etnia, de orientação sexual ou outro. Além do mais, tais modelos são tão bons quanto os dados que foram usados para construí-los. Outra preocupação reside na privacidade dos dados. Lembrando que dados são a matéria-prima dessas ferramentas.
Certo é que a liderança das gigantes americanas foi chacoalhada e que muitos outros modelos vão surgir em breve, mais baratos e melhores. A jornada está só no início!
Finalizamos, eu e o prof. Tsang, a primeira disciplina do CIn a abordar Generative Pre-trained Transformer (GPT) e Large Language Models (LLM), intitulada: GPT: métodos e desafios de modelos de linguagem. A disciplina foi oferecida para alunos de mestrado e de doutorado da pós-graduação em Ciência da Computação do CIn-UFPE.
Ao ser lançado, o ChatGPT nos fez refletir sobre várias possíveis direções quanto ao seu uso e quanto ao alcance de suas potencialidades. Aplicações como tradução, sumarização de documento, construção de textos, entre outras, atingiram novos patamares e deixaram vários métodos/estratégias/algoritmos obsoletos.
Para a construção de plataformas semelhantes ao ChatGPT, diversas tecnologias foram agregadas de forma inteligente para obtermos os resultados que enxergamos hoje. Uma dessas tecnologias consta na sigla do GPT, o “T” é de Transformers (mais detalhes neste link) que é uma rede neural para treinar LLMs em grandes bancos de dados.
Os LLMs transformaram a área de processamento de linguagem natural e compõem a base de uma ampla gama de sistemas de última geração que têm demonstrado uma excelente capacidade de gerar textos legíveis e fluidos. Porém, como toda nova tecnologia, esses modelos trazem consigo novos desafios, entre eles, desafios relacionados a aspectos éticos e de escalabilidade. A disciplina focou em fundamentos e, também, em diversos aspectos relacionados ao uso destes modelos.
Nesta primeira edição, o curso contou com a participação de 27 alunos (13 de doutorado e 14 de mestrado). Os orientadores desses alunos, no programa de pós-graduação do CIn, formam um grupo heterogêneo composto por 16 professores que atuam em diversas áreas, tais como: inteligência artificial, aprendizagem de máquina, ciência de dados, otimização, realidade aumentada e engenharia de software.
Esta diversidade trouxe desafios, mas, foi frutífera, em especial, nas discussões que expuseram pontos de vistas que, embora convergentes, tinham alvos díspares. Por outro prisma, esta diversidade também reforça a ubiquidade da aprendizagem de máquina nas mais diversas áreas de pesquisa.
Após o treinamento de uma máquina de aprendizagem, obtém-se um modelo M que é usado para classificar novas instâncias, ou seja, instâncias nunca vistas durante o processo de treinamento. Esse modelo funciona da seguinte maneira: recebe como entrada uma instância de teste (xq) e fornece como saída uma predição da classe (ωq) dessa instância, i.e., M(xq) → ωq.
Conforme descrito acima, observam-se duas fases: uma de treinamento, na qual o modelo M é gerado, e uma de teste, na qual o modelo é usado para classificar novas instâncias (xq). Mas, existem outras alternativas, por exemplo: no artigo Online local pool generation for dynamic classifier selection, os modelos só são treinados quando a instância de teste é apresentada ao sistema. Assim, os modelos são treinados on-the-fly, especificamente para classificar cada instância de teste e, depois da classificação, os modelos são descartados. Vale destacar que quando o sistema é colocado em execução, ele não possui nenhum classificador armazenado. Esse tipo de abordagem tem a vantagem ser facilmente adaptável à inclusão de novos dados de treinamento, mesmo quando o sistema está implantado no cliente.
Com o intento de unir esses dois mundos, propusemos um novo classificador que parte do processo de treinamento é feito offline e parte é feito online, chamado Perturbation-based Classifier(PerC). A parte offline é igual ao procedimento corriqueiro, descrito acima, no qual o conjunto de dados de treinamento é usado para gerar o modelo. Já o procedimento online, utiliza a instância de teste (xq), em tempo de execução, para auxiliar no processo de tomada de decisão da máquina de aprendizagem.
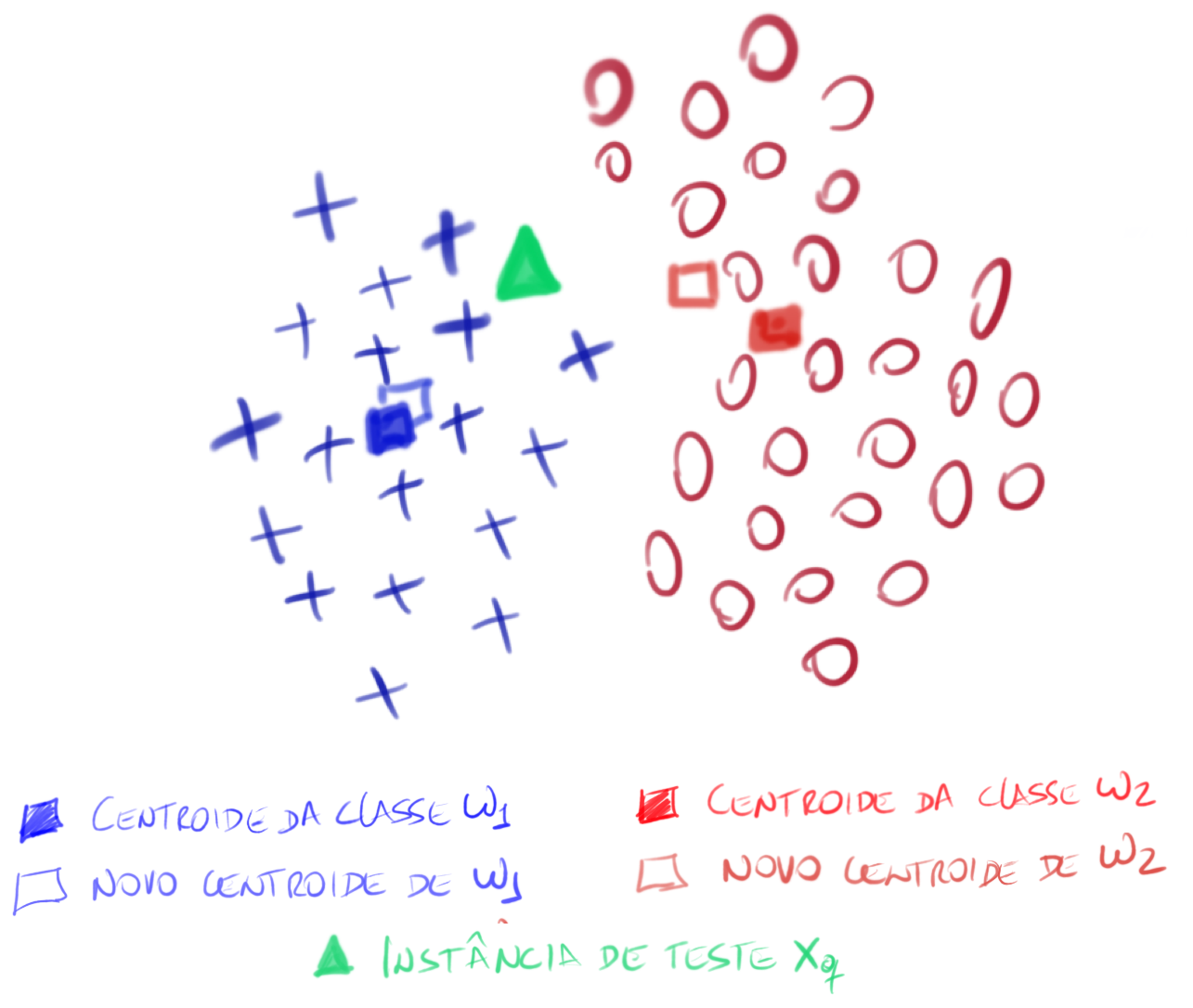
Para explicar o funcionamento da parte online, suponha um problema com duas classes (ω1 e ω2) e admita que a instância de teste xq pertence à classe ω1. Assim, é esperado que a inserção da instância xq na classe ω1 causará uma “perturbação” (daí o nome do classificador) menor do que sua inserção na classe ω2, pois xq pertence à classe ω1. Essa é a hipótese.
Para ilustrar o conceito de perturbação, a figura acima mostra uma tarefa simples composta de duas classes (ω1: azul e ω2: vermelha), na qual deseja-se classificar a instância de teste xq (representada pelo triângulo verde). Para cada uma das classes, é possível calcular seu centroide (centro de massa), representado por um quadrado preenchido da cor da classe.
O algortimo PerC adiciona xq ao conjunto de treinamento das classes, admitindo, momentaneamente, que tal instância pertence a cada uma das possíveis classes do problema. Assim, suponha que xq pertence à classe azul. Logo, o número de instâncias nessa classe será acrescido de um e, feito isso, recalcule seu centro de massa. Faça o mesmo para a classe vermelha: suponha que xq é uma instância vermelha e recalcule o centro de massa dessa classe. Os novos centros de massa são representados por quadrados vazados da cor de cada classe.
Depois do recálculo dos centros de massa, podemos verificar qual centro de massa sofreu maior variação em seu posicionamento original no espaço de características. O centro de massa da classe azul sofreu uma menor variação quando comparado ao centro de massa da classe vermelha. Logo, o PerC classificará xq como sendo da classe azul (ω1). Vale enfatizar que ao inserir xq na classe azul, o comportamento dessa classe mudou pouco, dando a entender que a instância adicionada já fazia parte da distribuição dessa classe. Observando a figura, notam-se que os quadrados preenchidos são calculados offline, enquanto os quadrados vazados só foram calculados online, usando a instância de teste (xq).
Para tarefas com mais de duas classes, ou seja, multi-classe, o PerC funciona da mesma forma. Ele adiciona, temporariamente, a instância de teste xq, em cada uma das classes, e avalia a perturbação causada. A classe que for minimamente perturbada é atribuída como sendo a classe da instância xq. Para fins de ilustração, nesse exemplo foi usada a média da classe como fator fundamental para a análise da perturbação. Mas, outros fatores podem ser levados em conta, tal como a matriz de covariância das classes.
PerC não pode ser categorizado como um sistema de online learning, pois a instância de consulta xq não é permanentemente adicionada ao conjunto de treinamento. No PerC, após a classificação, a instância xq é descartada. De maneira geral, PerC não pode ser enquadrado em nenhum paradigma de aprendizagem existente. É um novo paradigma.
Os avanços científicos e tecnológicos em processamento de linguagem natural têm o objetivo de intermediar a comunicação entre computadores e humanos usando seu principal meio de transmissão de informação, de conhecimento e de sentimento: a linguagem natural. A comunicação entre humanos é uma relação social bastante complexa que envolve o uso de diversos recursos, tais como: gestos e símbolos. Mas, dentre todos os meios, a palavra merece uma atenção especial, por sua abrangência e alcance.
A confluência entre palavras e sistemas de aprendizagem de máquina mostra um caminho para a produção de aplicações que agregam valor a diversas tarefas: tradução, detecção de fake news, deteção de hate speech, categorização de documentos, análise de sentimentos e de emoções, entre outras. Um pilar fundamental para o sucesso da automatização de tais aplicações reside na representação dessas palavras de uma forma que facilite a tarefa das máquinas de aprendizagem. Essa tal representação deve preservar o significado das palavras.
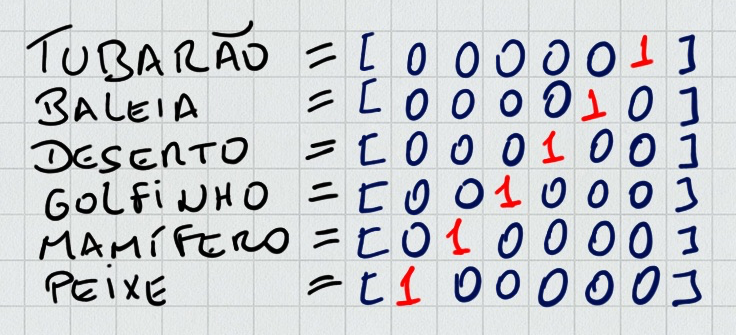
O WordNet é um dicionário de sinônimos de palavras em inglês. Além dos sinônimos, o WordNet armazena, para cada palavra, um conjunto de relações do tipo “é um”. Por exemplo: para a palavra morcego, as relações “é um” animal, “é um” mamífero, entre outras, podem ser recuperadas.Assim, o WordNet é uma alternativa para representar palavras, porém, possui algumas limitações. Uma delas refere-se a incompletude, ou seja, faltam sinônimos de várias palavras, especialmente, de palavras mais novas. Ao se analisar textos, algumas palavras aparecem regularmente próximas entre si, enquanto outras, raramente, aparecem juntas. Para exemplificar: as palavras “tubarão” e “baleia” ocorrem juntas com mais frequência do que as palavras “tubarão” e “deserto”. Logo, uma informação importante diz respeito à similaridade entre palavras, e isso, o WordNet também não oferece.
One-hot encoding
Até 2012, boa parte das aplicações representavam palavras usando uma codificação ortogonal. Para ilustrar, um corpus composto por seis palavras: tubarão, baleia, deserto, golfinho, mamífero e peixe, seria representado pelos vetores binários:
Essa forma de representar, também conhecida como one-hot encoding, traz consigo algumas questões. Em geral, um corpus (conjunto de textos) possui mais do que seis palavras. Dado que o tamanho do vetor, que representa cada palavra, é igual ao número de palavras no corpus, esse vetor terá, facilmente, o tamanho de algumas centenas de milhares de posições. Logo, são vetores grandes e esparsos (cada vetor possui apenas um valor “1” e vários “0”s).
Outro fator negativo ao empregar o one-hot encoding está relacionado à similaridade entre as palavras. Nessa representação, a distância entre quaisquer duas palavras é a mesma, pois cada palavra é um vetor perpendicular a todos os outros, logo, o produto interno entre dois vetores é igual a zero. Desta forma, a distância entre as palavras “baleia” e “golfinho” e as palavras “baleia” e “deserto” é a mesma. Nenhuma relação entre as palavras é estabelecida, e isso fere o objetivo de adicionar semântica ao processo, pois sabemos que as palavras “baleia” e “golfinho” aparecem mais frequentemente juntas do que as palavras “baleia” e “deserto”.
Word vectors
Tendo em vista que a relação entre as palavras é importante, pois é uma forma de adicionar semântica ao processo, alternativas foram desenvolvidas para incluir essa informação de contexto no vetor que representada cada palavra. Desde 2013, uma forma de mapear palavras em vetores com valores reais, estabeleceu-se como o estado da arte da área: word vectors (word embedding).
Ao contrário do one-hot enconding, no qual um vetor perpendicular às demais palavras é atribuído a cada palavra, os word vectors são aprendidos usando uma rede neural artificial. Esse processo de aprendizagem dos vetores leva em consideração o fato de que palavras que ocorrem em contextos similares possuem semânticas, também, similares. Dito de outra forma, se a palavra “peixe” aparece próxima da palavra “tubarão” mais frequentemente do que a palavra “mamífero”, é esperado que as palavras “peixe” e “tubarão” sejam mais “parecidas”, semanticamente, do que as palavras “peixe” e “mamífero”. Assim, deseja-se construir vetores que representem as palavras de forma que a distância entre “peixe” e “tubarão” seja menor do que a distância entre “peixe” e “mamífero”.
A figura a seguir mostra exemplos de word vectors nos quais é possível observar que as distâncias entre as palavras não é a mesma e que algumas relações semânticas, semelhantes às descritas no parágrafo anterior, são preservadas. Nota: cada uma das palavras dessa figura era formada originalmente por um vetor de cem valores e, para fins de visualização, a dimensionalidade foi reduzido para duas usando a análise dos componentes principais. Logo, muita informação foi perdida nesse processo de redução para uma representação 2D.
Mas, como embutir tal semântica nos vetores que representam as palavras, sabendo que tais vetores são compostos por números reais? Para ilustrar a intuição dessa construção dos vetores, veja o exemplo a seguir que mostra a frase “Focas, orcas, golfinhos e baleias são mamíferos que vivem nos mares”. Nesse exemplo, o elemento “central” é dado pela palavra “baleia” e os elementos de “contexto” estão destacados em verde. Esse processo é chamado de janelamento e, para essa ilustração, foi usado uma janela de tamanho cinco. De maneira iterativa, essa janela percorre a frase, colocando outras palavras como o elemento “central”.
Os valores que compõem o vetor da palavra “central” são atualizados de maneira que consigam predizer quais palavras formam o “contexto”. Na figura, wt representa a palavra central “baleia” e P(wt+2|wt) é a probabilidade de predizer a palavra “mamífero” (wt+2) dada a palavra “baleia” (wt). Desta forma, ao apresentar várias e várias janelas à máquina de aprendizagem, o modelo consegue aprender o contexto de palavras estimando a probabilidade de uma palavra no “contexto” ser predita pela palavra “central”. E, ao fim, esse processo “magicamente” embute o significado das palavras nos valores dos vetores. Para mais detalhes sobre o funcionamento do modelo, veja o artigo que propõe o Word2vec. Esse é o modelo seminal que usa uma rede neural para representar as palavras seguindo a intuição descrita acima.
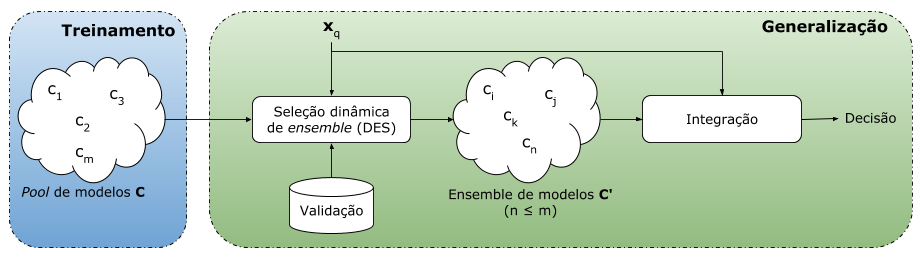
Um sistema de múltiplos classificadores (multiple classifier system — MCS) é composto por um pipeline de três etapas: geração, seleção e integração — conforme mostrado na figura a seguir.
Etapas de um sistema de múltiplos classificadores. [adaptada de Cruz et al. 2018]Pode-se observar essas três etapas de um MCS como uma caixa-preta que recebe como entrada um conjunto de treinamento (Γ), um conjunto validação e uma instância de teste (xq), e que fornece como saída, a classe (no caso de classificação) ou o valor predito (no caso de regressão ou previsão de séries temporais) da instância de teste. Da mesma forma que máquinas de aprendizagem monolíticas (árvore e decisão, redes neurais, entre outras), um MCS busca uma função capaz de predizer com eficácia o rótulo das instâncias que lhe são apresentadas durante a generalização. A seguir, são descritas as três etapas de um MCS.
Geração
Na primeira etapa, geração, as máquinas de aprendizagem são treinadas e armazenadas em um pool C que pode ser homogêneo ou heterogêneo. Por homogêneo, entende-se que todos os modelos do pool são treinados usando o mesmo algoritmo de aprendizagem, e.g., árvore de decisão. Por outro lado, em um pool heterogêneo, os modelos são treinados com diferentes algoritmos, tais como: árvore de decisão, perceptron e redes neurais.
Usar algoritmos diferentes é uma forma de aumentar a diversidade do pool; sendo essa uma vantagem de um pool heterogêneo. Porém, escolher quais algoritmos de aprendizagem devem ser usados, e quantos, é um problema desafiador. Daí, gerar um pool homogêneo é uma alternativa interessante por sua simplicidade.
Mesmo trabalhando com um pool homogêneo, é necessário que os modelos desse pool sejam diversos. Bagging (bootstrap aggregating) é um algoritmo comumente usado para esse fim e funciona da seguinte forma: dado um banco de dados de treinamento (Γ) com n instâncias, bagging gera m bancos de dados usando reamostragem com reposição. Cada banco de dados gerado tem o mesmo número de instâncias (n) do banco de dados original. Mas, como bagging é um procedimento com reposição, cada banco de dados terá instâncias repetidas. É esperado que 63,2% sejam instâncias únicas de Γ, e que, o restante, 36,8%, seja composto de instâncias repetidas. Cada um dos bancos de dados gerado por bagging é usado para treinar um modelo. Assim, ao fim do processo, m modelos são treinados, C = {c1, c2, …, cm}.
Dado que bagging usa um processo aleatório para adicionar instâncias a cada um dos bancos, pode-se afirmar, com alta probabilidade, que os bancos gerados são diferentes entre si. Diferença essa que auxilia na geração de modelos diversos. Além do bagging, outros algoritmos são usados para gerar o pool, entre eles: boosting, random subspacee rotation forest.
Seleção
Após a geração, a próxima etapa tem o objetivo de selecionar um subconjunto de modelos do pool que será usado para predizer a classe/valor da instância de teste. A seleção pode se dar de duas formas: estática ou dinâmica.
Seleçao estática [adaptada de Cruz et al. 2018]A seleção estática (static selection – SS) escolhe os melhores modelos do poolC que comporão o ensemble de modelos C’, sendo C’ ⊂ C. A figura acima mostra que esse processo é realizado offline, ou seja, durante o treinamento, e usa o conjunto de validação como guia para a escolha dos modelos. Na seleção estática, o mesmo subconjunto de modelos C’ é usado para classificar/predizer todas as instâncias de teste (xq).
Já na seleção dinâmica, os modelos selecionados podem diferir de uma instância de teste para outra; por esse motivo é chamada de dinâmica. Essa operação de seleção é realizada online, quando o sistema completo já está em operação, e depende da instância de teste que se deseja avaliar.
Seleção dinâmica de um modelo (ci) por instância de teste (xq) [adaptada de Cruz et al. 2018]Seleção dinâmica de um ensemble (C’) por instância de teste (xq) [adaptada de Cruz et al. 2018]As duas figuras acima mostram formas de selecionar dinamicamente modelos: a primeira seleciona apenas um modelo por instância de teste, enquanto a segunda seleciona um ensemble, um subconjunto do pool inicial.
A seleção dinâmica é motivada pelo fato de que nem todos os modelos no pool são competentes para predizer o rótulo de todas as instâncias de teste. Assim, deseja-se encontrar, por instância, os melhores especialistas (modelos) para realizar essa predição.
Integração
A etapa de seleção pode escolher um ou mais modelos. Se apenas um modelo for selecionado, não há integração. Nesse caso, a resposta do sistema é dada pela aplicação do modelo selecionado à instância de teste, i.e., ci(xq).
Sob outra perspectiva, se mais de um modelo for selecionado, é necessário o emprego de alguma regra para combinar as respostas dos modelos. Essas regras podem ser divididas em duas categorias: treináveis e não-treináveis. As não-treináveis levam esse nome pois são regras fixas que não necessitam de um processo de treinamento. Nessa categoria, o voto majoritário é a regra mais empregada. Nesta regra, cada modelo vota em uma classe e a classe com mais votos é atribuída como sendo o rótulo da instância de teste. Outros exemplos de regras não-treináveis são: média, produto, soma, mínimo e máximo.
Como o próprio nome indica, as regras treináveis são definidas por um processo de treinamento. Assim, usam-se máquinas de aprendizagem com o propósito de aprender a melhor função que integrará as respostas dos modelos selecionados. Qualquer máquina de aprendizagem pode ser usada para esse fim, e.g., árvore de decisão e multi-layer perceptrons.
Quando não se sabe a priori quantos modelos serão escolhidos pela etapa de seleção, as regras não-treináveis são mais usadas do que as treináveis, pois a maioria das máquinas de aprendizagem requerem um vetor de características de tamanho fixo. Além disso, as regras não-treináveis são mais simples e, por conseguinte, mais fáceis de interpretar.
Ao treinar uma máquina de aprendizagem, muitos desafios espreitam o horizonte, entre eles: overfitting. Uma das alternativas para minimizar overfitting é escolher a máquina correta para a tarefa que se deseja resolver. Por exemplo: se tivermos poucos dados disponíveis, uma rede neural artificial pode não ser a melhor escolha; embora existam estratégias para gerar dados artificiais e aumentar a quantidade de dados de treinamento, tais como oversampling e data augmentation. Uma escolha mais apropriada seria um algoritmo de instante-based learning, e.g., k-nearest neighbor.
Escolher o melhor algoritmo de aprendizagem, por tarefa, é uma problema em busca de solução. Muitas abordagens que se valem de meta-learning já foram propostas, mas ainda existe muito terreno a percorrer nesse campo. Essa é uma pesquisa bem interessante e motivada, também, por um teorema de nome engraçado, mas, extremamente importante para a área, chamado de no free lunch theorem. Esse teorema nos indica que não existe uma máquina de aprendizagem que seja a melhor para todas as tarefas. Ou seja, cada tarefa tem suas peculiaridades que devem ser melhor resolvidas por máquinas que tenham características distintas. Nota: um teorema é uma afirmação provada como verdadeira; logo, essa difere de uma mera opinião.
Consequentemente, é responsabilidade do especialista em aprendizagem a escolha da melhor máquina para resolver uma nova tarefa. Mas, existe outra alternativa…
Se para cada tarefa, uma máquina deve ser escolhida, por que não unir esforços e juntar várias máquinas para resolver essa tal tarefa? Vox Populi, Vox Dei. Esse “poder das multidões” (wisdom of the crowd) é a premissa da área de Combinação de Classificadores (ensemble learning) que possui vários nomes, tais como: sistemas de múltiplos classificadores e máquinas de comitê. Esses sistemas combinam máquinas com o intuito de melhorar a precisão geral do sistema, fundamentando-se no argumento de que a junção das opiniões de um grupo de indivíduos é melhor do que a opinião de apenas um indivíduo.
Em um experimento, no início do século vinte, SirFrancis Galton — o mesmo que desenvolveu um método eficiente para classificação de impressões digitais — combinou a resposta de 787 pessoas que estimaram o peso de um boi morto e vestido. Ao calcular a média das respostas de todos os participantes, Galton observou que o erro foi menor do que um porcento (link). Ao invés de combinar as respostas de todos, Galton poderia ter escolhido o indivíduo mais competente para estimar o peso. Entretanto, essa escolha não seria uma tarefa trivial, da mesma forma que, escolher a melhor máquina de aprendizagem, por tarefa, não é uma tarefa simples. Assim, ao combinar todas as respostas, a probabilidade de escolher um indivíduo incompetente foi minimizada.
É inútil combinar máquinas que tenham o mesmo comportamento, ou seja, máquinas que acertem e errem as mesmas instâncias. Assim, ao juntar várias máquinas em um pool, é esperado que elas tenham um excelente desempenho em partes diferentes do espaço de características. Em outras palavras, é fundamental que as máquinas sejam diversas entre si. Existem várias maneiras de se obter diversidade, entre elas: usar diferentes algoritmos de aprendizagem e usar dados diferentes para treinar cada uma das máquinas.
Razões para combinar máquinas
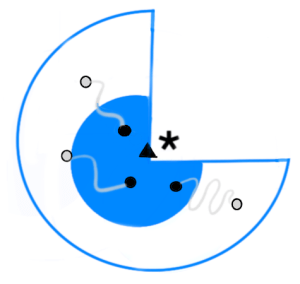
Os aspectos que fortalecem o uso de estratégias de combinação de classificadores podem ser aglutinados em: estatístico, computacional e representacional. A figura ao lado é usada para explicar esses três aspectos. Nela, vê-se que o “espaço dos bons modelos”, para uma dada tarefa, é um subconjunto do “espaço dos modelos”. Esses modelos são máquinas de aprendizagem, de classificação ou de regressão, que foram treinadas com dados de uma tarefa específica. Além disso, o asteriscos (∗) representa o classificar ideal, os círculos (•) são os classificadores individuais e o triângulo (Δ) representa a combinação dos classificadores (ensemble). Objetiva-se obter um modelo o mais próximo possível do modelo ideal (∗). Nota: essa figura foi adaptada da figura 3.2 do livro da Kuncheva, 2014.
Estatístico
Computacional
Representacional
Estatístico
Na figura que mostra o aspecto Estatístico, percebe-se que o modelo combinado (Δ) está bem mais próximo do modelo ideal (∗) do que a maioria dos modelos individuais (•). Vale salientar que o modelo combinado não é o melhor, pois existe pelo menos um modelo (•) que está mais próximo do modelo ideal do que o modelo combinado. Entretanto, por melhor que seja o seu procedimento experimental, a incerteza relacionada à precisão do modelo, aferida durante o treinamento, pode levar a escolha de um modelo inadequado. Assim, ao combinar os modelos, minimiza-se a chance de selecionar um modelo ruim.
Computacional
Durante o treinamento, um modelo é levado do “espaço dos modelos” para o “espaço dos bons modelos” — conforme mostrado pelas curvas em cinza na figura do aspecto Computacional. Cada um desses modelos (•) deve se posicionar em um mínimo local diferente da superfície de erro. Logo, a combinação desses modelos diversos gerará um modelo mais próximo do modelo ideal.
Representacional
Suponha que todos os modelos individuais (•) sejam lineares e que a tarefa, que se deseja resolver, seja não-linearmente separável. Logo, nenhum modelo, cuja representação é linear, será capaz de modelar essa tarefa. Por outro lado, ao combinar modelos lineares, regiões não-lineares podem ser modeladas. Assim, na figura que mostra o aspecto Representacional, percebe-se que o modelo combinado (Δ) está fora do “espaço dos modelos”, pois todos os modelo desse espaço são lineares e o alvo é um modelo não-linear que pode ser alcançado combinando modelos lineares. De maneira geral, regiões complexas de bordas entre classes podem ser modeladas usando modelos simples.
Não existe uma bala-de-prata para evitar overfitting. Boas práticas na condução de procedimentos experimentais, aliado ao entendimento do significado desse fenômeno,
contribuem para amenizar esse indesejável problema. Seguem alguns pontos a considerar para combater o overfitting.
treinar com mais dados
Se a máquina de aprendizagem usada é complexa, em termos da quantidade de parâmetros a ajustar, uma alternativa é adquirir mais dados com o intuito de equilibrar a quantidade de parâmetros versus a quantidade de instâncias de treinamento. Ou, simplesmente, deve-se escolher uma máquina mais simples, que tenha menos parâmetros.
validação cruzada
Uma das formas de realizar validação cruzada é usar o procedimento k-fold cross-validation. Nesse procedimento, o conjunto de dados é dividido em k partes, aproximadamente do mesmo tamanho, das quais, k-1 partes são usadas para treinar o modelo e a parte restante é usada para avaliar o modelo. Esse processo é repetido k vezes, de forma que cada parte será usada tanto para treinar como para avaliar o modelo. De maneira geral, a validação cruzada, por si só, não evita overfitting, mas segue uma boa prática ao separar o conjunto de teste e ao realizar um revezamento dos dados para uma melhor avaliação, no que tange a generalização do modelo em instâncias não vistas. Uma observação: o k-fold cross-validation não é uma boa opção quando o conjunto possui poucos dados.
parar o treinamento mais cedo (early stopping)
Máquinas de aprendizagem, tais como redes neurais artificiais, árvores de decisão, deep learning, entre outras, aprendem iterativamente. A cada passo, a máquina ajusta seus parâmetros aos dados e isso pode ser monitorado. Pode-se usar esse monitoramento para decidir qual é o melhor momento de interromper o treinamento da máquina. Espera-se que a precisão no conjunto de treinamento aumente com o tempo, mas, em relação ao conjunto de validação, a acurácia deve atingir um pico e depois cair. Esse pode ser um bom momento para frear o treinamento, antes que a máquina se sobreajuste aos dados.
regularização
Regularização é um conceito amplo que envolve várias técnicas com o propósito de produzir modelos que melhor se ajustem aos dados, evitando overfitting. Um exemplo é o procedimento de poda em uma árvore de decisão. Esse consiste em eliminar alguns “galhos” que, uma vez removidos, reduzirá a árvore, tornando-a mais simples e menos específica às instâncias de treinamento. Outros exemplos de técnicas de regularização envolvem dropout em redes neurais e adição de parâmetros de penalização na função de custo.
ensemble
Ensemble learning, ou sistema de múltiplos classificadores – SMC -, combina as saídas de vários modelos com o intuito de melhorar a resposta final do sistema. Os SMCs têm alcançado resultados melhores do que o uso de modelos isolados. Esse sucesso deve-se a divisão de tarefas que é o espírito dessa área. Baseado no princípio de dividir-para-conquistar, cada modelo que compõe o SMC é treinado com parte do conjunto de treinamento e, consequentemente, acaba por se tornar um especialista nessa porção. Essa estratégia ajuda a amenizar o overfitting, e além disso, é robusta à presença de ruído nos dados.
Overfitting (sobreajuste ou superajuste) é, provavelmente, o maior problema em aprendizagem de máquina. Ele ocorre quando um modelo não é capaz de generalizar. Ou seja, o modelo classifica corretamente os dados que foram usados para treiná-lo, mas, não consegue reproduzir esse desempenho em dados novos, que lhe são apresentados durante seu uso em produção. Logo, assume-se que o modelo “decorou” os dados usados para treiná-lo e, por conseguinte, seu desempenho nos dados de treinamento é bastante superior ao seu desempenho em uso, frustrando as expectativas do cliente.
Para ilustrar, suponha que o treinamento de uma máquina de aprendizagem, usando um conjunto de treinamento Τ, gerou um modelo, e que, esse modelo foi avaliado no conjunto de teste Δ. As taxas de acerto do modelo, nos conjuntos Τ e Δ, foram de 95 e 92%, respectivamente. Logo, a expectativa é que, em uso, a acurácia do modelo gire em torno dos noventa porcento. Mas, ao ser colocado em produção, esse modelo não ultrapassa os 70% de acerto. Essa perda de 20 pontos percentuais, pode ser oriunda de várias fontes, uma delas é overfitting. Mas, o que ocorreu?
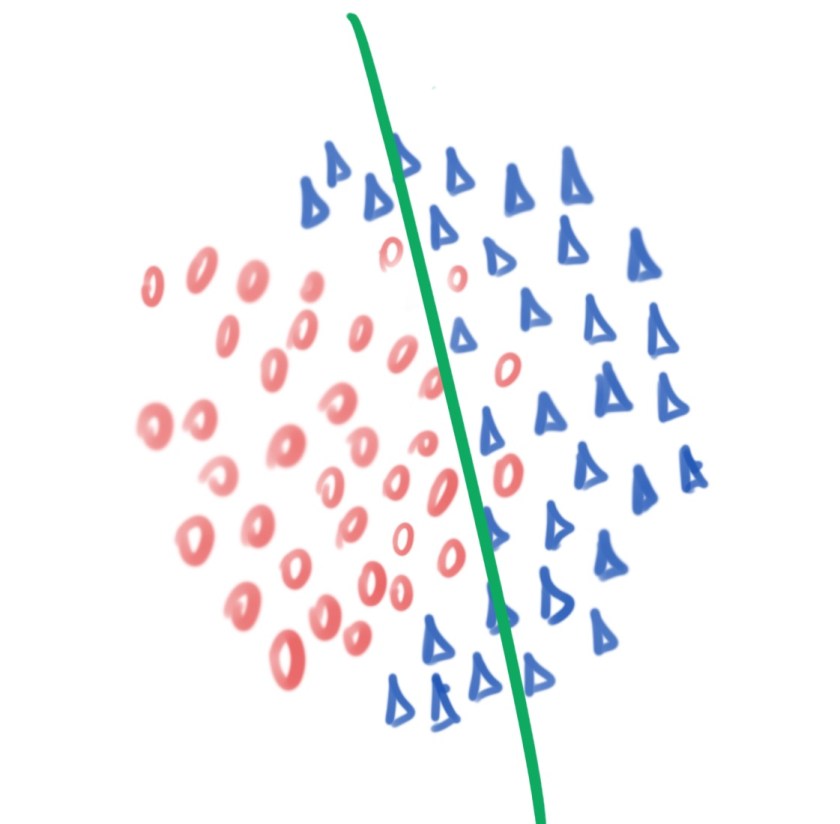
(a) underfitting
(b) overfitting
(c) fitting
Vamos usar um exemplo para explicar o ocorrido. A figura acima mostra três cenários que diferem na função aprendida (modelo que é mostrado em verde) a partir dos dados de treinamento. Veja que na figura (a), o modelo classifica incorretamente muitas instâncias. Já na figura (b), o modelo não erra nenhuma instância, a separação é perfeita. A diferença entre as figuras (a) e (b) está no ajuste dos modelos. Enquanto o modelo da figura (a) não conseguiu aprender a estrutura dos dados (underfitting), o modelo da figura (b) fez uma estimativa muito precisa e acabou por “decorar” as instâncias de treinamento (overfitting). Um caso desejado é apresentado na figura (c), na qual, o modelo se ajusta aos dados, mas de forma a capturar as estruturas das classes e, consequentemente, poder generalizar bem instâncias nunca vistas.
Em outras palavras, caso um modelo bastante simples seja usado, pode-se subestimar e não capturar a complexidade dos dados. Observe que, na figura (a), a região de decisão é não-linearmente separável, logo, uma reta não é capaz de resolver o problema. Por outro lado, ao usar uma função muito complexa (popularmente: um canhão para matar uma mosca), corre-se o risco de decorar as instâncias de treinamento (figura (b)) e, dessa forma, perde-se a capacidade de classificar corretamente instâncias não usadas no treinamento. Vale salientar que a maioria das instâncias que serão incorretamente classificadas concentram-se na borda, perto da região de decisão, entre as classes. Já as instâncias mais internas às classes, essas são facilmente classificadas por qualquer algoritmo (mas, essa é uma discussão para outro post).
Avaliações incorretas geram modelo com overfitting
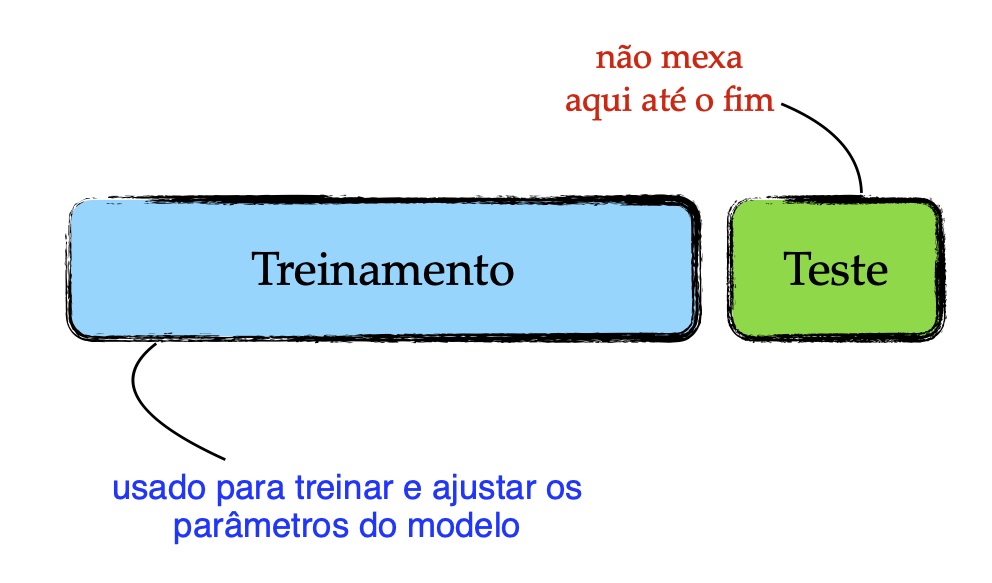
A maneira mais comum de se incorrer em overfitting é treinar e avaliar a máquina usando o mesmo conjunto de dados. Suponha a situação na qual o professor passa listas de exercícios durante o curso e, na prova, repete questões dessas listas. Nesse caso, é esperado que os alunos que aprenderam as questões das listas, não terão nenhuma dificuldade em acertar todas as questões da prova. Dessa forma, as notas não refletirão a capacidade dos alunos em resolver problemas semelhantes aos que foram apresentados nas listas de exercícios; pois, os alunos devem ser avaliados em questões diferentes das usadas nas listas de exercícios. Com base nessa analogia, as máquinas devem ser avaliadas usando dados diferentes dos dados que foram usados para treiná-las.
Mesmo quando são usados dois conjuntos disjuntos, um para treinar a máquina e outro para testá-la, não há garantia de que o overfitting será evitado. Isso ocorre quando procedimentos metodológicos incorretos são empregados, tais como: uso de informações dos dados de teste e overfitting no conjunto de validação.
Usando informações do conjunto de teste
Aprendizagem de máquina é a arte de ajustar parâmetros. São muitos parâmetros para avaliar e uma pergunta recorrente é: quais parâmetros devo usar e em quais circunstâncias? Uma forma comum de abordar essa questão é usar o seguinte procedimento: primeiro, define-se um conjunto de parâmetros, depois, a máquina é treinada e, por fim, o modelo gerado é avaliado no conjunto de teste. Até aí, tudo bem! Mas, se esse processo for repetido com um conjunto diferente de parâmetros, teremos, ao final, dois modelos, cada um treinado com parâmetros diferentes. Como escolher o melhor deles? Se escolhermos olhando para o resultado dos modelos no conjunto de teste, essa escolha está fadada a overfitting, pois, o conjunto de teste foi usado no processo de escolha dos parâmetros. Existem variações desse procedimento incorreto que, por princípio, ferem a premissa de não usar o conjunto de teste no processo de ajuste/escolha do modelo.
Overfitting no conjunto de validação
Modificando um pouco o procedimento descrito acima, ao invés de se ter dois conjuntos, dividimos os dados em três conjuntos disjuntos: treinamento, validação e teste. O objetivo do conjunto de validação é auxiliar o treinamento da máquina, buscando os melhores parâmetros, similar ao procedimento acima, mas, deixando o conjunto de teste fora do processo. Esse parece ser um procedimento mais confiável, pois, o conjunto de teste, no qual o modelo será avaliado, está, de fato, ausente do processo de treinamento. Perceba que o procedimento de ajuste dos parâmetros pode se repetir diversas vezes, mas o conjunto de validação é o mesmo. Assim, após várias tentativas, um conjunto de parâmetros que satisfaça a métrica usada será encontrado, porém, esse modelo estará sobreajustado ao conjunto de validação.
O desenvolvimento de sistemas, que usam algoritmos de aprendizagem de máquina, segue um fluxo diferente das abordagens tradicionais. A fonte dessa diferença reside na premissa básica de qualquer algoritmo de aprendizagem: extração de conhecimento a partir de dados históricos. Assim, são descritas a seguir, cinco etapas para a construção de soluções que baseiam-se em aprendizagem de máquina.
Dado que os algoritmos de aprendizagem de máquina “aprendem” a partir de dados, a primeira etapa é a aquisição dos dados. O conjunto de informações coletadas pode ser armazenado de várias maneiras: sistema gerenciador de banco de dados, planilhas, ou mesmo em arquivo texto. Importante ressaltar que esses dados serão usados para treinar/calibrar o modelo (a máquina de aprendizagem), logo, devem representar toda a diversidade da tarefa sob investigação. Em outras palavras, não conjecture que o sistema irá classificar um pássaro como sendo beija-flor-tesoura, nome científico eupetomena macroura, se nenhum beija-flor dessa espécie está presente nos dados.
Os dados coletados na etapa anterior devem ser tratados com o intuito de prepará-los para o processo de treinamento do algoritmo de aprendizagem. Alguns procedimentos comuns são: seleção de variáveis, redução de instâncias, extração de características, imputação de dados faltantes e análise de outliers. Vale salientar que esse processamento, muitas vezes, está atrelado ao algoritmo de aprendizagem que será usado na etapa seguinte. Isso se dá, pois, algoritmos diferentes, possuem requisitos diferentes. Por exemplo: alguns algoritmos lidam apenas com dados que estejam representados com valores numéricos, outros apenas com valores categóricos. Logo, é necessário converter variáveis categóricas em numéricas, ou vice-versa, dependendo do algoritmo.
Nessa etapa, o algoritmo de aprendizagem de máquina, que melhor adere aos dados, é escolhido para treinar o modelo. Essa escolha deve levar em consideração vários pontos, entre eles: quantidade de instâncias e de variáveis no banco de dados e existência de desbalanceamento entre as classes. Além disso, deve-se atentar ao tipo de aprendizagem: supervisionado, não-supervisionada, semi-supervisionada ou por reforço. E, no caso de ser supervisionado, se o problema é de classificação ou de regressão. Dentre os modelos mais comumente usados, é possível citar: árvore de decisão, redes neurais multi-layer perceptron, random forest, support vector machines, k-nearest neighbours, XGBoost, logistic regression, k-means, naive bayes, apriori e expectation-maximization. Por fim, vale destacar os sistemas de múltiplos classificadores (ensemble learning) que, ao invés de usar apenas uma máquina, combinam várias máquina de aprendizagem, a fim de melhorar a precisão final do sistema.
O modelo treinado deve ser avaliado para que seja possível predizer sua precisão em uso. Várias medidas podem ser usadas para aferir a performance do modelo e, a escolha da medida depende da tarefa que se deseja resolver. Exemplos de medidas: acurácia, f-score e curva ROC. Vale ainda frisar que o modelo deve ser avaliado com dados diferentes dos que foram usados para treiná-lo. Assim, os dados devem ser divididos em dois conjuntos disjuntos: treinamento (usada para treinar o modelo) e teste (usado para avaliar o modelo). Quando a estimative de desempenho de um modelo, em dados nunca vistos (dados de teste), é otimista, diz-se que ocorreu overfitting. Esse é, provavelmente, o maior problema de aprendizagem de máquina.
Após a avaliação do modelo, caso o desempenho esperado não tenha sido alcançado, faz-se necessário aperfeiçoar o modelo. As possíveis causas dessa inadequação devem ser investigadas e, caso necessário, retorna-se para a aquisição de novos dados (etapa 1), para o processamento dos dados de um forma diferente (etapa 2) e/ou para o treinamento de um novo modelo, possivelmente, usando um algoritmo de aprendizagem diferente (etapa 3).
Um dos pontos que devemos atentar ao treinar uma máquina de aprendizagem é o desbalanceamento entre as classes. Podemos dizer que as classes estão desbalanceadas quando o número de padrões em uma classe é muito menor do que o número de padrões numa classe diferente.
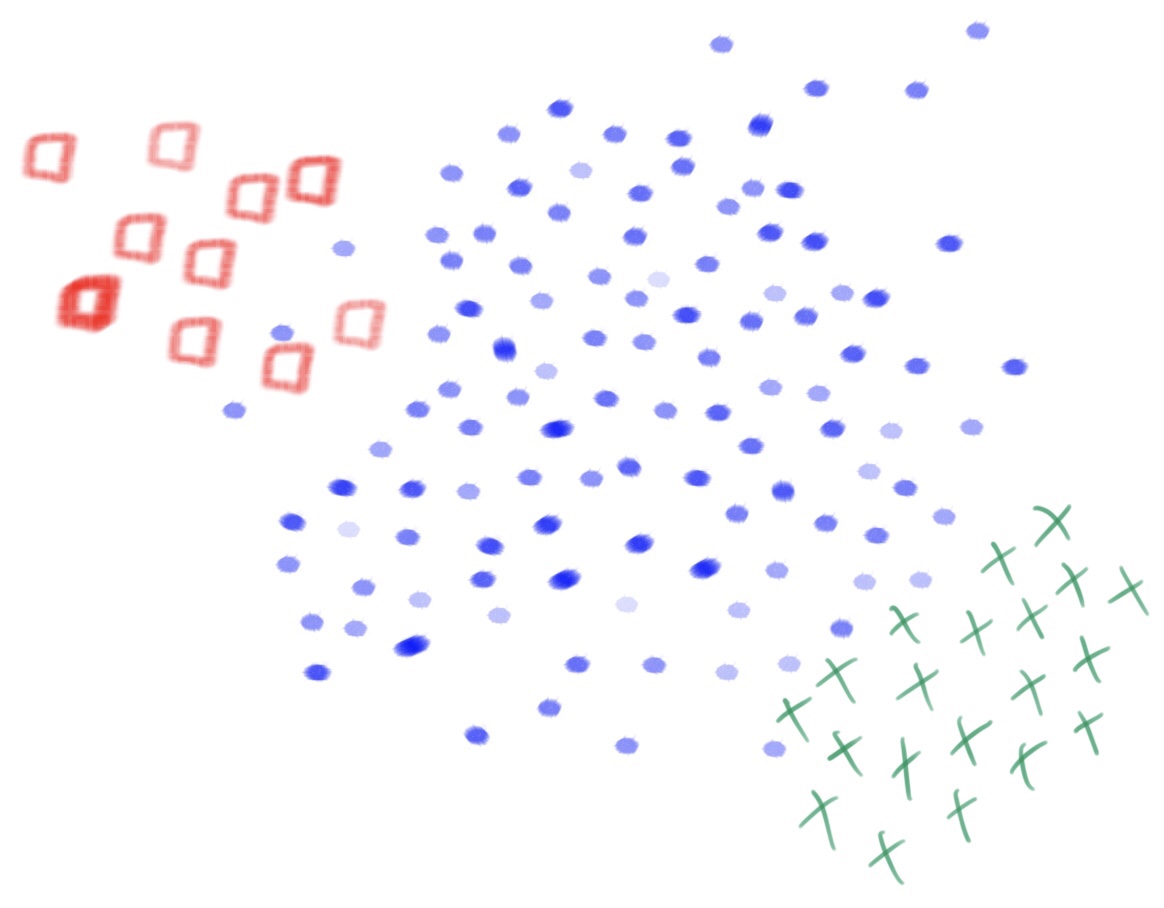
Veja o exemplo na figura acima que mostra duas classes: azul e vermelha. Nesse conjunto, temos 100 padrões da classe azul e 10 da classe vermelha. Logo, a quantidade de padrões na classe azul é 10 vezes maior do que a quantidade de padrões na classe vermelha. O imbalance ratio (IR) é usado para medir esse desbalanceamento, e é calculado como sendo a razão entre o número de padrões na classe majoritária e o número de padrões na classe minoritária. Para esse exemplo, o IR é igual a 10, pois temos uma razão de um para dez (1:10).
Em muitos problemas do mundo real, esse desbalanceamento é bem mais acentuado. Vamos supor um cenário no qual a razão fosse de 1:1000, ou seja, para cada padrão da classe vermelha, temos mil padrões da classe azul. Nesse cenário, caso uma máquina de aprendizagem sempre respondesse “classe azul”, para qualquer padrão fornecido como entrada, essa máquina atingiria uma acurácia (número de acertos dividido pelo número total de padrões avaliados) próxima a cem porcento. Para ser mais preciso, supondo um conjunto com 3003 padrões, sendo 3 da classe vermelha e 3000 da classe azul (para manter a proporção de 1 para 1000), a acurácia seria de 3000/3003, ou seja, 99,9001% de acerto.
Embora essa taxa de acerto, superior a 99,9%, seja bastante promissora, vale salientar que essa máquina de aprendizagem, de fato, não “aprendeu” nada. Ela, de certa forma, foi guiada a minimizar o erro no conjunto de treinamento (com ampla maioria de padrões da classe azul) e, nesse caso, o treinamento pode tê-la levado a desprezar os padrões da classe vermelha.
No exemplo acima, uma máquina conseguiu quase cem porcento de acerto, mesmo sem aprender a tarefa de maneira relevante. Para esses casos, a acurácia não é uma medida interessante, pois é uma medida global, calculada sem fazer distinção entre as classes. Quando avaliamos conjuntos de dados desbalanceados, devemos utilizar medidas que avaliem as classes separadamente, por exemplo: f-score, g-mean e area under the ROC curve.
É fato que várias máquinas de aprendizado podem, de maneira enviesada, priorizar a classe majoritária durante o seu treinamento. Assim, as principais alternativas para lidar com conjuntos de dados, nos quais as classes estejam desbalanceadas são:
pré-processamento: o objetivo é deixar todas as classes com um número similar de padrões, ou seja, balancear as classes. Técnicas de undersampling (remover padrões da classe majoritária) e/ou de oversampling (adicionar padrões na classe minoritária) são empregadas;
algoritmo com penalização: os algoritmos de aprendizagem são modificados com o intuito de torná-los sensíveis à questão do desbalanceamento. Assim, durante o processo de treinamento da máquina, o custo ao errar um padrão da classe minoritária é bem maior do que o custo associado a um erro na classe majoritária;
ensemble: nessa abordagem, técnicas de pré-processamento são usadas em conjunto com sistemas de múltiplos classificadores. Desta forma, ao invés de centralizar o conhecimento em apenas uma máquina de aprendizagem, o conhecimento extraído dos dados de treinamento é dividido em várias máquinas.
Das três alternativas listadas acima, a mais comumente usada é a primeira: pré-processamento. Embora, seja importante destacar a última, ensemble, pois essa tem alcançado resultados superiores quando comparada às demais (artigo).
E para tarefas multi-classe?
A questão fica um pouco mais sutil, quando temos mais de duas classes. Veja o exemplo na figura a seguir.
Observando essa imagem, podemos dizer que a classe verde é minoritária em relação à classe azul e majoritária em relação à classe vermelha. Assim, a relação entre as classes já não é tão óbvia quanto em problemas com duas classes. Além disso, o cálculo do IR, conforme descrito anteriormente, não representa uma medida tão confiável. Isso acontece porque diferentes conjuntos de dados podem ter o mesmo IR, desde que, a proporção, entre a quantidade de padrões na classe com mais exemplos e a quantidade de padrões na classe com menos exemplos, seja mantida. Note que, o IR do exemplo com três classes, é o mesmo do exemplo com duas classes: 10; pois, no cálculo do IR, o número de exemplos nas demais classes (que não seja a classe majoritária e a classe minoritária) não é levado em consideração. Mas, existem outras formas de calcular o IR, por exemplo: dividindo o número de exemplos na classe majoritária pela soma das quantidades de padrões de todas as outras classes. Assim, o IR para o problema para três classes ficaria igual a 3,33, ou seja, cem padrões da classe azul dividido por trinta (20 padrões da classe verde mais 10 da classe vermelha).
É relevante destacar, que essa questão do desbalanceamento entre classes, é mais grave quando lidamos com tarefas que dispõem de poucos padrões. Para tarefas, nas quais o número de padrões é extremamente alto para todas as classes, essa questão é minimizada. Ao acessar muitos padrões, podemos construir um conjunto de treinamento balanceado, basta realizar undersampling na classe majoritária.
Além disso, o desbalanceamento, por si só, não representa um problema! Basta que as classes (mesmo que desbalanceadas) estejam bem separadas no espaço de características, consequentemente, a tarefa da máquina de aprendizagem será bem simples. Veja, que no exemplo acima, as classes vermelha e verde, embora desbalanceadas, são linearmente separáveis. Logo, um Perceptron (uma reta) seria suficiente para realizar uma classificação perfeita dos exemplos dessas classes. A dificuldade emerge quando, além de desbalanceadas, as classes se sobrepõem. Observe que as bordas, entre as classes vermelha e azul e entre as classes azul e verde, são mais complexas de serem definidas.
Quando tomamos uma decisão, usamos uma grande quantidade de variáveis e de hierarquias de variáveis. Muitas vezes, nem nos apercebermos da importância dessas variáveis, pois, a complexidade de algumas decisões está além do nosso entendimento. Para ilustrar: você poderia me explicar, em detalhes, como reconhece seu amigo? Quais características, seus sistemas (visual, auditivo, …) analisam, a fim de identificá-lo com precisão?
Ok, vamos para um exemplo mais palpável. Suponha que desejamos comprar um carro. De pronto, nos vem a mente, uma série de variáveis que devemos avaliar: preço, cor, consumo de combustível, procedência, entre outras. Essas características nos ajudam a decidir, se iremos ou não comprar o carro.
De maneira similar, o conjunto de características, que apresentamos à máquina de aprendizagem, é de imperativa importância para que ela consiga tomar a melhor decisão. A escolha dessas características é uma tarefa não trivial, principalmente, quando não temos um especialista para nos ajudar no problema que desejamos resolver (e.g., comprar um carro usado sem a ajuda de um mecânico).
Em aprendizagem de máquina, essas características (features, em inglês), também chamadas de variáveis ou atributos, são fundamentais para o sucesso do processo de aprendizagem. Mas, geralmente, não sabemos quais são as características mais relevantes, consequentemente, decidimos por usar um grande número de características. Assim, corre-se o risco de que algumas delas sejam irrelevantes ou mesmo prejudiciais para o treinamento da máquina de aprendizagem. Com o objetivo de reduzir essa quantidade de características e por conseguinte, aliviar a maldição da dimensionalidade, a alternativa mais comum é usar algoritmos de seleção de características. Esses algoritmos têm o papel de buscar o melhor subconjunto de características, a fim de realizar com sucesso, a tarefa que temos em mãos.
Mas, para selecionar características, precisamos, em primeiro lugar, ter as características. Essas características podem ser obtidas de duas formas: manual (handcraftedfeatures) ou podem ser aprendidas (featurelearning).
Na primeira forma, handcraftedfeatures, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 1, 2, 3, 4).
Dado que <manual> featureengineering é uma tarefa cara e difícil, como evitá-la? Uma alternativa é construir máquinas capazes de realizar essa tarefa automaticamente. Ou seja, ao invés da busca ser feita por humanos, podemos delegar a tarefa de encontrar as melhores características para um algoritmo. Esse procedimento é chamado de featurelearning (mostrado como sendo o caminho inferior da imagem acima). A boa notícia é que algumas máquinas já fazem esse trabalho. Arquiteturas de aprendizado profundo (deeplearning – DL) estão sendo usadas para esse fim, especialmente, para tarefas que envolvam imagens, voz e texto.
Não é à toa, que DL tem se destacado nas manchetes dos noticiários ultimamente. Ela tem obtido resultados bem superiores às handcrafted features em várias aplicações, e esse sucesso deve-se ao fato de que as características são aprendidas a partir dos dados do problema. Em outras palavras, essas características são automaticamente extraídas dos dados originais, por algoritmos que buscam minimizar o erro global do sistema. Logo, o conjunto de características gerado é dependente do problema, ou seja, são personalizadas para cada conjunto de dados de treinamento.
Ganha-se em precisão, perde-se em interpretabilidade. Essa é uma desvantagem de DL. As características aprendidas não possuem explicação conhecida no mundo real. Nesse sentido, o processo realizado pela DL, ao aprender as características, é, de certa forma, semelhante ao processo que trilhamos, por exemplo, ao reconhecer uma pessoa. Sabemos que funciona… mas não conseguimos explicar em detalhes como realizamos essa tarefa.
Outro fator limitante está relacionado à abrangência. Sabemos como aprender automaticamente características interessantes, quando os dados de entrada são imagens, voz e texto. O desafio agora é expandir esse aprendizado automático para outras aplicações, que ainda requerem a manufatura de características.
Você já deve ter ouvido a frase: “a inteligência artificial está em todo lugar”. É verdade que usamos no nosso cotidiano vários dispositivos e aplicações que se valem de algoritmos inteligentes e nem percebemos. Algoritmos que filtram imagem impróprias, que recomendam possíveis amigos e que escolhem suas melhores fotos estão embutidos nas redes sociais. Quando um email é colocado na caixa de Spam, uma máquina de aprendizagem (ramo de destaque da inteligência artificial) fez essa classificação. Os resultados das suas buscas na Internet são filtradas e selecionadas usando, adivinha o quê, algoritmos de aprendizagem de máquina. Recomendação de produtos, detecção de fraudes em compras, carros autônomos; a lista é vasta!
O sucesso da aprendizagem de máquina nas mais diversas áreas desperta nosso interesse em imaginar quais serão as próximas aplicações que permearão nossas vidas. Um exercício interessante é entender o que essas aplicações de sucesso têm em comum. Mas, talvez esse seja um exercício mais mercadológico do que propriamente um exercício técnico. Por outro lado, do ponto de vista técnico, vale a pena investigar a essência por trás do uso de aprendizagem de máquina. Para abordar esse assunto, devemos analisar três fatores:
Dados — a aprendizagem de máquina é essencialmente um processo de aprendizado a partir de dados. Logo, sem dados, outras alternativas, diferentes da aprendizagem de máquina, devem ser buscadas. Para um processo de aprendizado supervisionado, os dados devem ser rotulados. Exemplificando: num sistema de detecção de spam, os dados devem ser formados por emails e cada email deve ter um rótulo indicando se ele é spam ou não. Assim, de posse dos emails e de seus rótulos, uma máquina de aprendizagem pode encontrar uma função que ao receber um email como entrada, consegue inferir se é spam ou não.
Função — o processo de treinamento de uma máquina de aprendizagem tem o objetivo de encontrar uma função que faz um mapeamento de um conjunto de variáveis de entrada em uma das possíveis saídas. No caso de um sistema de detecção de spam, se a função que faz esse mapeamento já for conhecida, é desnecessário gastar tempo obtendo os dados e treinando uma máquina para se obter o que já se tem. Mas, se essa função for desconhecida e você não conseguir criar um modelo do problema — como é o caso de verificar se um email é spam —, métodos de aprendizagem de máquina podem te ajudar.
Padrão — os dados que serão usados para o treinamento de uma máquina de aprendizagem devem apresentar um comportamento coerente em relação aos objetos do mundo real que eles representam. Imagine um email que hoje é rotulado como spam e amanhã, esse mesmo email, é rotulado como não-spam. Essa inconsistência impossibilita que uma máquina de aprendizagem construa uma representação plausível do que é um spam, pois não é possível encontrar um comportamento padrão que possa ser usado para fins de aprendizagem.
Avaliando esses três fatores, podemos verificar que mesmo se os dados não tiverem um comportamento coerente (padrão) e se a função de mapeamento for conhecida, podemos usar técnicas de aprendizagem de máquina. Nada nos impede. Mas, não conseguiremos usar aprendizagem de máquina se não tivermos dados. Esse é um pré-requisito essencial.
Para os que pretendem construir soluções baseadas em aprendizagem de máquina para a indústria, sugiro atentar para outros fatores, tais como:
Os responsáveis devem ter um bom entendimento do que aprendizagem de máquina significa e o que pode ser alcançado com seu uso. Por mais que iniciativas de automação end-to-end do processo de aprendizagem, e.g. Auto-ML, tenham crescido bastante nos últimos anos, o emprego acurado de técnicas de aprendizagem requer a intervenção de especialistas;
Dados de qualidade devem estar disponíveis. Para tanto, devem ser observados o tamanho e a diversidade da amostra, bem como sua aderência ao problema real. A máquina será tão boa quanto os dados usados para treiná-la. Caso a máquina seja treinada com uma amostra que não reflete o mundo real, a aplicação provavelmente não funcionará a contento. Digamos que um sistema tenha sido treinado apenas com imagens coletadas durante o verão e com forte luz solar. Esse sistema, muito provavelmente, terá o seu funcionamento comprometido para imagens adquiridas à noite, durante um inverso chuvoso;
Existência de um processo claro de avaliação do diferencial ao empregar aprendizagem. Essa avaliação possui várias camadas que pode ter início no módulo mais interno do sistema — métrica usada para avaliar a máquina de aprendizagem —, a uma apreciação global que quantificará uma possível redução de custos ou de riscos do negócio.
Por fim, gostaria de destacar que a falta de entendimento do que pode ser alcançado usando aprendizagem de máquina dá origem ao mito de que basta termos uma grande massa de dados e, milagrosamente, técnicas de aprendizagem serão capazes de resolver qualquer problema apenas “olhando” esses dados. Essa massa de dados, muitas vezes, precisa ser trabalhada a várias mãos por diferente especialistas (bancos de dados, ciência dos dados, estatísticos, experts no problema em questão, entre outros) para que tenhamos sucesso no uso de métodos que aprendem.
A ciência da computação é vasta e formada de várias subáreas, entre elas: teoria da computação, banco de dados, redes, engenharia de software, inteligência computacional e arquitetura. Como tal, encontrar uma metodologia universal para validar toda e qualquer pesquisa realizada na grande área parece-me utopia. <para quem leu os artigos listados no primeiro parágrafo> Entendo que o uso de experimentos não só ajudam, como não atrapalham; o problema é outro, pelo menos nas cercanias.
Decerto é que o foco da pesquisa, independente da subárea, deve estar na novidade e não apenas na precisão. Esse é um ponto importante pois é fácil encontrar artigos, ditos científicos que quando muito são tecnológicos, e até pesquisadores que justificam suas pesquisas pelo fato de terem encontrado uma boa precisão usando alguma medida. Vale salientar que a quantidade de medidas existentes é enorme e, derivado desse fato, encontrar pelo menos uma medida que justifique o modelo proposto pode ser questão de paciência. Veja esse artigo que lista mais de 30 medidas comumente usadas na área de mineração de dados.
Pesquisas dessa natureza muitas vezes se assemelham a colchas de retalhos compostas pela justaposição de diversas abordagens e que parecem ter surgido por obra do acaso ou por tentativa e erro. Nesses casos, justificar a motivação de tais pesquisas torna-se um pandemônio. Pois, as motivações de fato nunca foram pensadas, e agora que boas taxas de acerto foram obtidas é necessário pensar às avessas. Aí, o objetivo da pesquisa passa a ser encontrar uma justificativa que suporte a medida. <e quando tal justificativa não é encontrada? Resposta curta: comece novamente. Resposta longa: discutiremos isso em outro momento>.
Obter resultados muito bons não é ruim. Muito pelo contrário, em especial para a indústria que busca soluções para o mercado sempre ávido por diferenciais que desbanquem a concorrência. Por outro lado, para o crescimento do “conhecimento científico” precisamos de algo mais. Precisamos de premissas que suportem nossas ideias, pois assim, podemos colocar mais um degrau na escada que ajudará outros pesquisadores a galgar na direção da expansão do conhecimento científico.








 Esse “poder das multidões” (
Esse “poder das multidões” (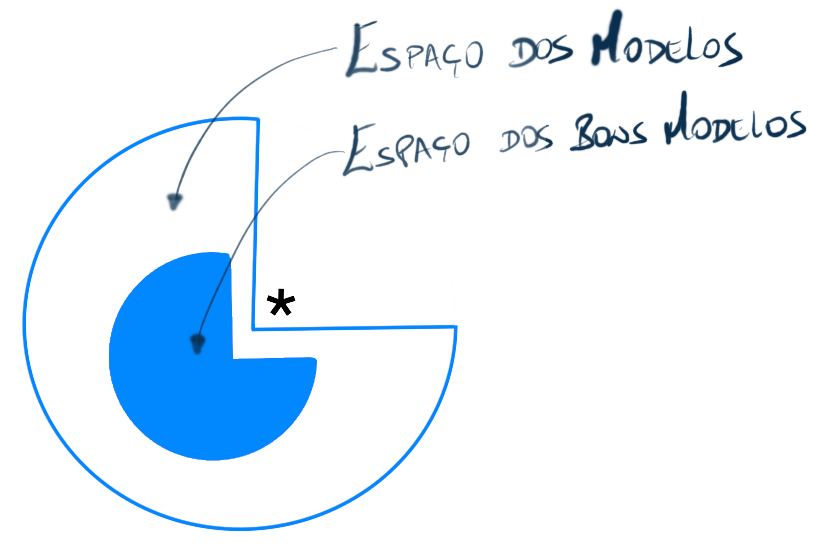 Nela, vê-se que o “esp
Nela, vê-se que o “esp










 Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links:
Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 
