Sistemas que extraem informações de grandes quantidades de textos (large language models – LLM) têm despertado os mais diferentes sentimentos e atiçado o interesse de variados setores da sociedade. Um exemplo de LLM é o ChatGPT que conseguiu atingir a incrível marca de mais de um milhão de usuários em apenas cinco dias após seu lançamento.
Embora o ChatGPT tenha causado bastante “barulho” nos últimos meses, a tecnologia que o tornou possível vem sendo desenvolvida há tempos.
A “magia” por trás do ChatGPT deve-se, principalmente, a um tipo de arquitetura de rede neural artificial chamada de Transformers que foi lançada num artigo da Google de 2017 intitulado Attention is all you need. Lembrando que o T da sigla GPT significa Transformer; Generative Pre-trained Transformer (GPT).
A arquitetura do Transformer (mostrada na figura acima) é composta de vários módulos e parece complicada de início, porém, notem que vários módulos se repetem. Neste post, foco nas três principais inovações que tornaram essa tecnologia realidade:
- Positional encoding;
- Attention;
- Self-attention.
A primeira, positional encoding, objetiva atribuir ordem as palavras de uma sentença quando apresentadas a modelos de aprendizagem de máquina. Já as duas seguintes, attention e self-attention, buscam pelas partes (palavras) mais importantes das sentenças. Mais detalhes a seguir.
Positional encoding
A ordem das palavras numa sentença importa. Logo, ao apresentar uma sentença a uma máquina de aprendizagem, é relevante informar para esta máquina a ordem das palavras. Esta é a tarefa do positional enconding.
De maneira simples, podemos dizer que o positional encoding atribui um número para cada palavra da sentença. Por exemplo: a frase
“Vamos jogar vôlei”
seria representada assim
[(“Vamos”, 1), (“jogar”, 2), (“vôlei”, 3)].
Esta é uma operação crucial, pois as redes neurais artificiais não levam em conta a ordem das palavras que lhes são apresentadas. Desta forma, a rede neural pode aprender que a primeira palavra está atrelada ao “1”, a segunda ao “2” e assim por diante.
Antes dos Transformers, as redes neurais recorrentes (RNN) atacaram esta questão da ordem das palavras de uma maneira diferente. Ao invés de apresentar todas as palavras da sentença de uma vez, as RNNs apresentavam uma palavra por vez à rede. Assim, a primeira palavra da sentença era apresentada à rede, em seguida, a segunda palavra e assim por diante. Mas, esta estratégia possui um alto custo de processamento e dificulta a paralelização das operações durante o treinamento da rede. Além disso, o trabalho de “entender” a ordem era atribuído à rede, no caso das RNNs, enquanto que nos Transformers, esta responsabilidade foi incorporada aos dados fornecidos como entrada para a rede.
Vale destacar que a estratégia usada no Transformer é mais sofisticada do que o exemplo mostrado acima que apenas atribuir números a cada palavra. Uma codificação usando as funções seno e cosseno, com diferentes frequências, são usadas para este fim. Mais detalhes sobre esta codificação pode ser encontrada aqui e aqui.
Attention
Antes de iniciar esta parte, lembremos que o artigo seminal do Transformer foi intitulado Attention is all you need. Logo, “attention” está no título do artigo e possui um papel crucial.
O conhecimento necessário para se chegar ao ponto que estamos em relação aos LLMs representa um aglomerado de experiências prévias. Neste sentido, o conceito de attention para a tradução foi descrito no artigo Neural machine translation by jointly learning to align and translate, em 2015.
Neste artigo, os autores destacam a importância de ter uma visão geral do texto para realizar uma tradução, por exemplo, de uma sentença do inglês para o francês de maneira mais acurada. Para ilustrar o conceito, a sentença
“The agreement on the European Economic Area was signed in August 1992.”
pode ser traduzida para
“L’accord sur la zone économique européenne a été signé en août 1992.”.
Perceba que quando da tradução de “European Economic Area” para “la zone économique européenne“, existe uma troca de ordem entre palavras. Além disso, francês, assim como o português, é uma língua na qual é necessário ajustar os adjetivos “économique” e “européenne” para o feminino por causa do termo “la zone“. Essas restrições dificultam bastante a possiblidade de se fazer uma tradução palavra-a-palavra de uma língua para a outra, como era comum em abordagens prévias.
Ainda no artigo de 2015, os autores mostram o heatmap, copiado acima, que relaciona cada palavra da sentença em inglês com palavras da sentença em francês. Perceba que devido à mudança de ordem das palavras de uma língua para a outra, neste heatmap, a palavra “European” está fortemente relacionada às palavras “économique” e “européenne“. Assim, este heatmap ilustra o mecanismo de attention que tem o objetivo de olhar para as diferentes alternativas quando da tradução.
Self-attention
A intuição por trás de self-attention é que nós não damos a mesma importância a todas as palavras em uma sentença. Logo, self-attention é um mecanismo que cria um relacionamento entre palavras de uma mesma sentença, com o intuito de focar em algumas, enquanto outras palavras recebem pouca atenção.
Tal mecanismo pode ajudar no processo de desambiguação entre palavras que possuem a mesma escrita e significados diferentes, por exemplo.
Observe estas duas sentenças:
“O real continua pouco valorizado comparado ao euro.”
“Isto não é real; estamos num ambiente virtual.”
A palavra real nas duas sentenças possuem significados diferentes e ao olhar para as outras palavras de cada sentença, podemos inferir o seu verdadeiro significado. Isso é realizado de maneira direta por humanos, simplesmente olhando as palavras ao redor.
Desta forma, na primeira sentença, a palavra “real” pode ser correlacionada a palavra “euro” e, assim, entende-se que o assunto trata de moedas. Já na segunda, a palavra “real” relaciona-se mais fortemente com a palavra “virtual”, e daí, inferimos que a palavra “real” não se trata de moeda, como na primeira sentença.
Não apenas o ChatGPT se beneficiou de Transformers. A lista é longa, entre elas: GPT, GPT-2, GPT-3, GPT-4, BERT, ALBERT, RoBERTa, DistilBERT e XLNet.







 Esse “poder das multidões” (
Esse “poder das multidões” (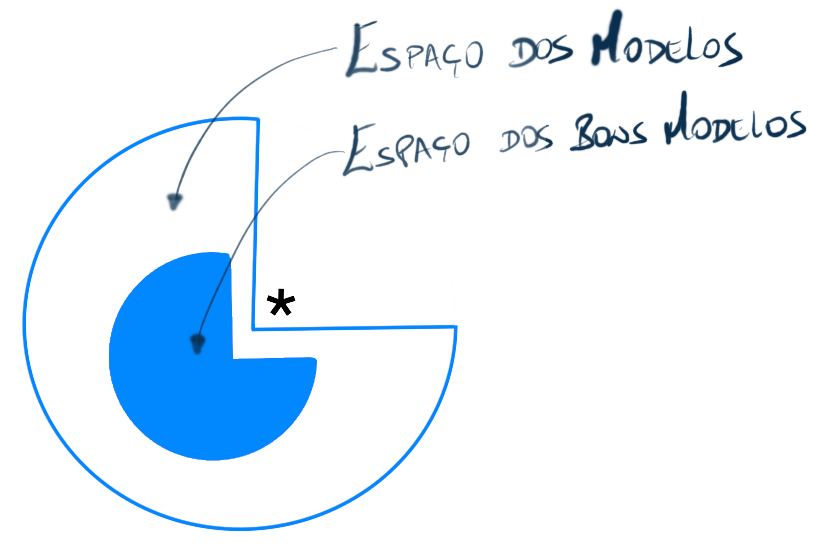 Nela, vê-se que o “esp
Nela, vê-se que o “esp
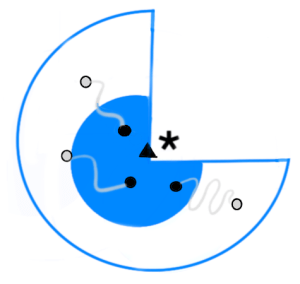







 Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links:
Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 