
O algoritmo k-vizinhos mais próximos (do inglês, k-Nearest Neighbors – kNN) funciona da seguinte forma: dada uma instância de teste xq, o algoritmo encontra os k vizinhos mais próximos de xq no conjunto de treinamento. Em seguida, a classe de xq é dada pela classe que ocorrer com maior frequência entre os k vizinhos.

Na figura acima, são mostrados os cinco vizinhos mais próximos da instância de teste xq. Dessas cinco instâncias, 4 são da classe “+” (vermelha) e 1 da classe “0” (azul). Ao aplicar o kNN, com k=5, a instância xq é classificada como sendo da classe vermelha, pois essa classe possui mais representantes na vizinhança de xq.
Esse algoritmo possui dois parâmetros: o número de vizinhos (k) e a medida de dissimilaridade (ou de similaridade) usada para encontrar os vizinhos mais próximos. A distância Euclidiana é a medida mais amplamente usada para determinar os vizinhos, embora existam diversas opções. Em relação ao parâmetro k (número de vizinhos), várias alternativas para determinar o valor mais adequado por tarefa podem ser empregadas. Uma delas é avaliar o algoritmo kNN no conjunto de validação, adotando diferentes valores para k. O valor de k que alcançar a melhor precisão será escolhido para classificar todas as instâncias de teste.
Uma primeira diferença em relação a outras máquinas de aprendizagem, tais como árvore de decisão e multi-layer perceptron, é que, no kNN, a etapa de treinamento é caracterizada apenas pelo armazenamento das instâncias. A rigor, não há treinamento. Logo, a função que será usada para a tomada de decisão é definida em operação, analisando um subconjunto dos dados de treinamento, i.e., os k vizinhos mais próximos. Por esse motivo, pode-se dizer que o kNN é uma máquina de aprendizagem local.
Embora seja simples, vale destacar que o kNN constrói regiões de decisão não-lineares no espaço de características. Para ilustrar, a figura a seguir mostra como o espaço de características bidimensional é dividido quando emprega-se o kNN, com k=1. As linhas verdes delimitam a área de cobertura de cada uma das instâncias de treinamento (pontos pretos: x1, x2 e x3). Assim, qualquer instância de teste que se posicionar na região amarela será classificada como sendo da mesma classe da instância x1, pois essa será a instância mais próxima. Da mesma forma, instâncias localizadas na região laranja serão classificada pela classe de x2 e, na região azul, pela classe de x3.
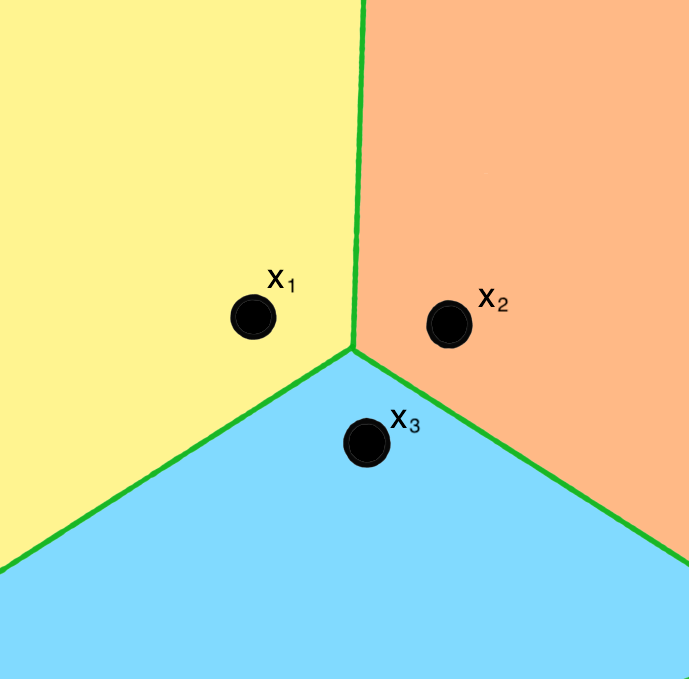
Importante destacar que as regiões de cobertura mostradas na figura foram obtidas usando apenas um vizinho mais próximo (1NN). Ou seja, essas regiões podem ficam mais complexas ao adotar valores maiores de k. Além disso, uma caraterísticas interessante do kNN é que as regiões de coberturas podem ser facilmente modificadas ao inserir, remover ou reposicionar as instâncias.
Mas, o kNN possui algumas desvantagens:
Armazenamento: todas as instâncias de treinamento são armazenadas para posterior consulta, quando da chegada de uma instância de teste. Se o conjunto de treinamento possuir muitas instâncias, a quantidade de memória requerida para armazená-lo pode ser um problema. Uma alternativa, para aliviar essa questão, é usar algoritmos de redução de instâncias que têm o intuito de reduzir o número de instâncias no conjunto de treinamento.
Esforço computacional: a função que classificará uma instância de teste, só é definida em operação, usando os vizinhos mais próximos. Logo, o kNN requer um esforço de processamento, em tempo de execução, para vasculhar todo o conjunto de treinamento em busca dos vizinhos para cada instância de teste. Algoritmos de redução de instâncias também podem auxiliar para mitigar essa desvantagem do kNN.
Alta dimensionalidade: ao calcular a dissimilaridade (por exemplo: usando a distância Euclidiana) entre vetores que são representados por muitas variáveis, esse cálculo pode ser impreciso devido à alta dimensionalidade dos vetores. Uma maneira de atenuar essa questão é remover variáveis redundantes ou pouco relevantes, para fins de classificação, usando algoritmos de seleção ou de extração de características.
A figura a seguir mostra dois exemplos que ilustram uma instância de teste e seus cinco vizinhos mais próximos. Nesses dois exemplos, percebe-se que a instância de teste xq está bastante próxima das instâncias da classe “0” (azul). Mas, o kNN (k=5) classificará as duas instâncias de teste como pertencentes à classe “+” (vermelha), pois essa classe possui mais instâncias do que a classe azul na vizinhança de xq.

Nesses exemplos, a proximidade de xq em relação aos seus vizinhos não é levada em consideração. Apenas a quantidade de instâncias na vizinhança é usada para decidir a classe de xq. Mas, é possível encontrar variações do kNN que visam abrandar essa e outras propriedades previamente discutidas.


