
Mesmo sendo desenvolvidos para problemas que tenham apenas dados de uma classe, one-class classifiers (OCCs) também podem ser usados para tarefas que possuem várias classes. Nesse caso, um OCC é treinado para cada classe. Logo, para uma tarefa com n classes, n OCCs serão treinados. A classificação de uma nova instância é realizada da seguinte forma: essa instância é fornecida como entrada para cada um dos OCCs e sua classe é definida como a classe do OCC que responder com maior certeza.
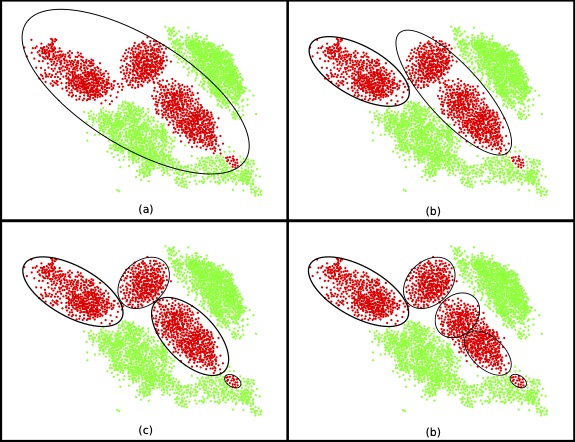
Entretanto, quando uma nuvem de instâncias é multimodal, ou seja, quando essa nuvem possui mais de um grupo, boa parte dos OCCs não consegue lidar com essa dificuldade. Suponha que os pontos vermelhos na figura (a) acima pertençam à classe target e os pontos verdes à classe outlier. Vale destacar que durante o processo de treinamento do OCC, apenas os pontos vermelhos estão disponíveis. Assim, os pontos em verde são mostrados na figura apenas para fins de ilustração. A elipse em preto representa o classificador OCC e engloba todos os pontos vermelhos, dividindo a área do espaço de características em duas: target (dentre da elipse) e outlier (fora da elipse). Nessa figura, é possível notar que vários exemplos da classe outlier estão localizados dentro da região delimitada pelo OCC e, por consequência, esses pontos são incorretamente classificados como pertencentes à classe target. Nota-se também que as instâncias em vermelho compõem uma classe multimodal, ou seja, formada por várias modas/grupos.
Uma alternativa para lidar com essa multi-modalidade é criar várias meta-classes, uma para cada grupo, e treinar um OCC por grupo. Logo, uma nuvem de pontos (uma classe) será representada por vários OCC, um para cada meta-classe ou grupo. O desafio é definir o número de grupos em uma nuvem de pontos e, para esse fim, pode-se usar cluster validity indices para estimar este número.
Entretanto, não existe um índice (cluster validity index) que consiga definir de maneira precisa todos os grupos de qualquer nuvem de pontos, pois tal tarefa depende da medida de distância usada, da estrutura dos dados e de outras características. Em outras palavras, um dado índice pode ser a melhor escolha para uma classe e não ser para outra. Logo, esse mapeamento, do melhor índice por classe, é um problema em aberto. Além disso, quando os cluster validity indeces são aplicados a uma dada nuvem de pontos, eles podem separar essa nuvem de maneiras diferentes. Por exemplo, o índice Silhouette pode indicar que a nuvem possui 3 grupos, enquanto o índice NbClust pode indicar 5 grupos.
Diante deste contexto, foi proposto o método One-class Classifier Dynamic Ensemble Selection for Multi-class problems (MODES) que é um sistema de seleção dinâmica de classificadores para tarefas multi-classe. O MODES usa vários índices e treina um OCC para cada grupo definido por cada um dos índices. Essa estratégia permite que a diversidade das informações extraídas pelos índices seja incorporada ao sistema através do treinamento de vários OCCs. Por exemplo: a figura (b) ilustra que um dado cluster validity index encontra dois grupos; assim, dois OCC são treinados, um para cada grupo. Já outros cluster validity indexes encontram 4 e 5 grupos, como mostrado nas figuras (c) e (d), respectivamente; e, mais nove OCCs são treinados. Assim, cada OCC torna-se um especialista em uma determinada área do espaço de caraterística e minimiza o erro de classificar um outiler como target, como ocorre na figura (a).
Vale destacar que no MODES cada classe é tratada individualmente, logo, desbalanceamento entre as classes não é uma preocupação. Além disso, estratégias que decompõem as classes, como é o caso do MODES, podem se apresentar como alternativas interessantes para incremental learning e para open-set recognition.
O MODES propõe uma abordagem capaz de lidar com dados que possuem distribuições complexas usando uma estratégia que seleciona dinamicamente os OCCs mais competentes para cada uma das instâncias de teste.
Rogério CP Fragoso, George DC Cavalcanti, Roberto HW Pinheiro, Luiz S Oliveira. Dynamic selection and combination of one-class classifiers for multi-class classification. Knowledge-based Systems, 2021.


