
Quando tomamos uma decisão, usamos uma grande quantidade de variáveis e de hierarquias de variáveis. Muitas vezes, nem nos apercebermos da importância dessas variáveis, pois, a complexidade de algumas decisões está além do nosso entendimento. Para ilustrar: você poderia me explicar, em detalhes, como reconhece seu amigo? Quais características, seus sistemas (visual, auditivo, …) analisam, a fim de identificá-lo com precisão?
Ok, vamos para um exemplo mais palpável. Suponha que desejamos comprar um carro. De pronto, nos vem a mente, uma série de variáveis que devemos avaliar: preço, cor, consumo de combustível, procedência, entre outras. Essas características nos ajudam a decidir, se iremos ou não comprar o carro.
De maneira similar, o conjunto de características, que apresentamos à máquina de aprendizagem, é de imperativa importância para que ela consiga tomar a melhor decisão. A escolha dessas características é uma tarefa não trivial, principalmente, quando não temos um especialista para nos ajudar no problema que desejamos resolver (e.g., comprar um carro usado sem a ajuda de um mecânico).
Em aprendizagem de máquina, essas características (features, em inglês), também chamadas de variáveis ou atributos, são fundamentais para o sucesso do processo de aprendizagem. Mas, geralmente, não sabemos quais são as características mais relevantes, consequentemente, decidimos por usar um grande número de características. Assim, corre-se o risco de que algumas delas sejam irrelevantes ou mesmo prejudiciais para o treinamento da máquina de aprendizagem. Com o objetivo de reduzir essa quantidade de características e por conseguinte, aliviar a maldição da dimensionalidade, a alternativa mais comum é usar algoritmos de seleção de características. Esses algoritmos têm o papel de buscar o melhor subconjunto de características, a fim de realizar com sucesso, a tarefa que temos em mãos.
Mas, para selecionar características, precisamos, em primeiro lugar, ter as características. Essas características podem ser obtidas de duas formas: manual (handcrafted features) ou podem ser aprendidas (feature learning).
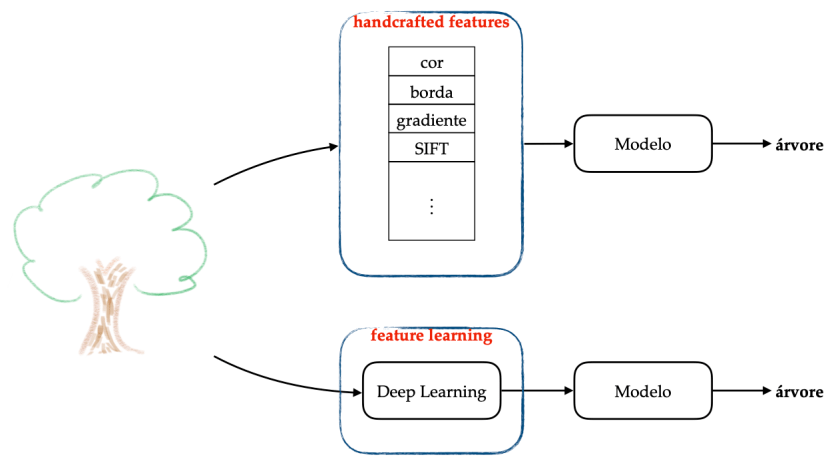 Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 1, 2, 3, 4).
Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 1, 2, 3, 4).
Dado que <manual> feature engineering é uma tarefa cara e difícil, como evitá-la? Uma alternativa é construir máquinas capazes de realizar essa tarefa automaticamente. Ou seja, ao invés da busca ser feita por humanos, podemos delegar a tarefa de encontrar as melhores características para um algoritmo. Esse procedimento é chamado de feature learning (mostrado como sendo o caminho inferior da imagem acima). A boa notícia é que algumas máquinas já fazem esse trabalho. Arquiteturas de aprendizado profundo (deep learning – DL) estão sendo usadas para esse fim, especialmente, para tarefas que envolvam imagens, voz e texto.
Não é à toa, que DL tem se destacado nas manchetes dos noticiários ultimamente. Ela tem obtido resultados bem superiores às handcrafted features em várias aplicações, e esse sucesso deve-se ao fato de que as características são aprendidas a partir dos dados do problema. Em outras palavras, essas características são automaticamente extraídas dos dados originais, por algoritmos que buscam minimizar o erro global do sistema. Logo, o conjunto de características gerado é dependente do problema, ou seja, são personalizadas para cada conjunto de dados de treinamento.
Ganha-se em precisão, perde-se em interpretabilidade. Essa é uma desvantagem de DL. As características aprendidas não possuem explicação conhecida no mundo real. Nesse sentido, o processo realizado pela DL, ao aprender as características, é, de certa forma, semelhante ao processo que trilhamos, por exemplo, ao reconhecer uma pessoa. Sabemos que funciona… mas não conseguimos explicar em detalhes como realizamos essa tarefa.
Outro fator limitante está relacionado à abrangência. Sabemos como aprender automaticamente características interessantes, quando os dados de entrada são imagens, voz e texto. O desafio agora é expandir esse aprendizado automático para outras aplicações, que ainda requerem a manufatura de características.
