
Overfitting (sobreajuste ou superajuste) é, provavelmente, o maior problema em aprendizagem de máquina. Ele ocorre quando um modelo não é capaz de generalizar. Ou seja, o modelo classifica corretamente os dados que foram usados para treiná-lo, mas, não consegue reproduzir esse desempenho em dados novos, que lhe são apresentados durante seu uso em produção. Logo, assume-se que o modelo “decorou” os dados usados para treiná-lo e, por conseguinte, seu desempenho nos dados de treinamento é bastante superior ao seu desempenho em uso, frustrando as expectativas do cliente.
Para ilustrar, suponha que o treinamento de uma máquina de aprendizagem, usando um conjunto de treinamento Τ, gerou um modelo, e que, esse modelo foi avaliado no conjunto de teste Δ. As taxas de acerto do modelo, nos conjuntos Τ e Δ, foram de 95 e 92%, respectivamente. Logo, a expectativa é que, em uso, a acurácia do modelo gire em torno dos noventa porcento. Mas, ao ser colocado em produção, esse modelo não ultrapassa os 70% de acerto. Essa perda de 20 pontos percentuais, pode ser oriunda de várias fontes, uma delas é overfitting. Mas, o que ocorreu?
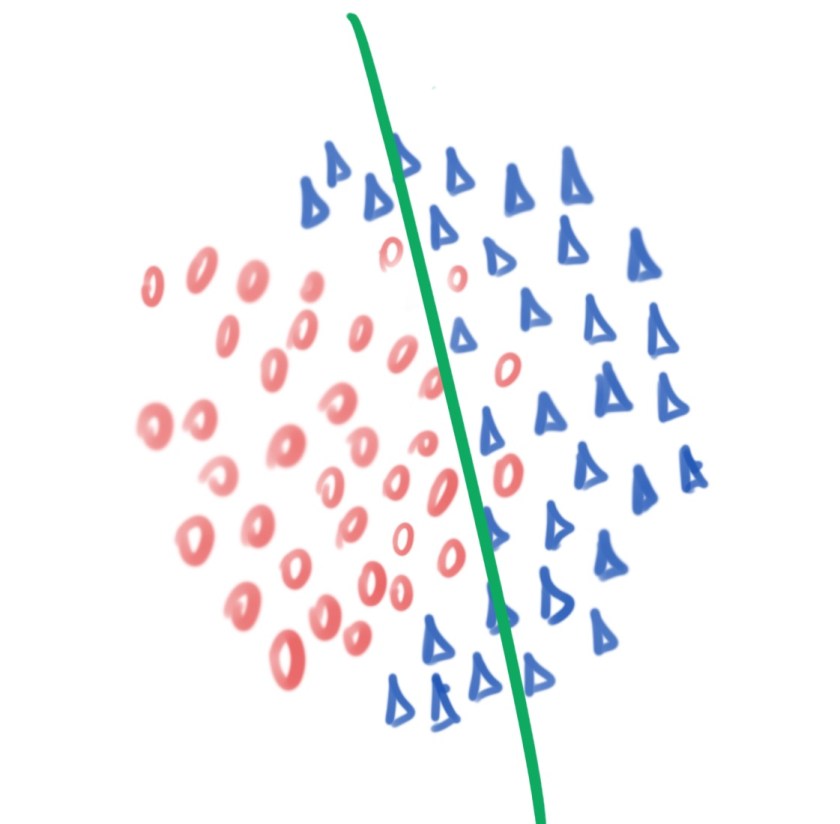


Vamos usar um exemplo para explicar o ocorrido. A figura acima mostra três cenários que diferem na função aprendida (modelo que é mostrado em verde) a partir dos dados de treinamento. Veja que na figura (a), o modelo classifica incorretamente muitas instâncias. Já na figura (b), o modelo não erra nenhuma instância, a separação é perfeita. A diferença entre as figuras (a) e (b) está no ajuste dos modelos. Enquanto o modelo da figura (a) não conseguiu aprender a estrutura dos dados (underfitting), o modelo da figura (b) fez uma estimativa muito precisa e acabou por “decorar” as instâncias de treinamento (overfitting). Um caso desejado é apresentado na figura (c), na qual, o modelo se ajusta aos dados, mas de forma a capturar as estruturas das classes e, consequentemente, poder generalizar bem instâncias nunca vistas.
Em outras palavras, caso um modelo bastante simples seja usado, pode-se subestimar e não capturar a complexidade dos dados. Observe que, na figura (a), a região de decisão é não-linearmente separável, logo, uma reta não é capaz de resolver o problema. Por outro lado, ao usar uma função muito complexa (popularmente: um canhão para matar uma mosca), corre-se o risco de decorar as instâncias de treinamento (figura (b)) e, dessa forma, perde-se a capacidade de classificar corretamente instâncias não usadas no treinamento. Vale salientar que a maioria das instâncias que serão incorretamente classificadas concentram-se na borda, perto da região de decisão, entre as classes. Já as instâncias mais internas às classes, essas são facilmente classificadas por qualquer algoritmo (mas, essa é uma discussão para outro post).
Avaliações incorretas geram modelo com overfitting
A maneira mais comum de se incorrer em overfitting é treinar e avaliar a máquina usando o mesmo conjunto de dados. Suponha a situação na qual o professor passa listas de exercícios durante o curso e, na prova, repete questões dessas listas. Nesse caso, é esperado que os alunos que aprenderam as questões das listas, não terão nenhuma dificuldade em acertar todas as questões da prova. Dessa forma, as notas não refletirão a capacidade dos alunos em resolver problemas semelhantes aos que foram apresentados nas listas de exercícios; pois, os alunos devem ser avaliados em questões diferentes das usadas nas listas de exercícios. Com base nessa analogia, as máquinas devem ser avaliadas usando dados diferentes dos dados que foram usados para treiná-las.
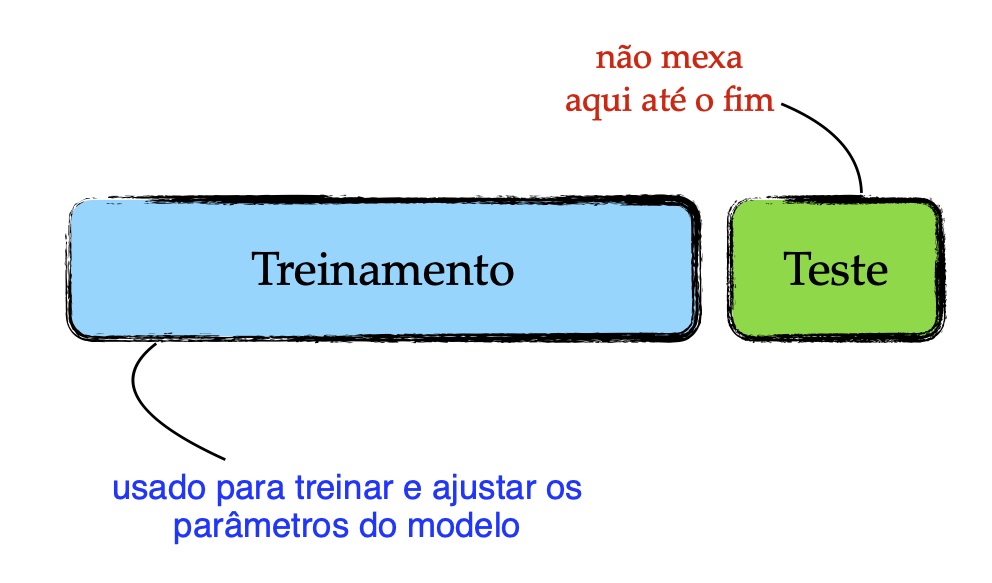
Mesmo quando são usados dois conjuntos disjuntos, um para treinar a máquina e outro para testá-la, não há garantia de que o overfitting será evitado. Isso ocorre quando procedimentos metodológicos incorretos são empregados, tais como: uso de informações dos dados de teste e overfitting no conjunto de validação.
Usando informações do conjunto de teste
Aprendizagem de máquina é a arte de ajustar parâmetros. São muitos parâmetros para avaliar e uma pergunta recorrente é: quais parâmetros devo usar e em quais circunstâncias? Uma forma comum de abordar essa questão é usar o seguinte procedimento: primeiro, define-se um conjunto de parâmetros, depois, a máquina é treinada e, por fim, o modelo gerado é avaliado no conjunto de teste. Até aí, tudo bem! Mas, se esse processo for repetido com um conjunto diferente de parâmetros, teremos, ao final, dois modelos, cada um treinado com parâmetros diferentes. Como escolher o melhor deles? Se escolhermos olhando para o resultado dos modelos no conjunto de teste, essa escolha está fadada a overfitting, pois, o conjunto de teste foi usado no processo de escolha dos parâmetros. Existem variações desse procedimento incorreto que, por princípio, ferem a premissa de não usar o conjunto de teste no processo de ajuste/escolha do modelo.
Overfitting no conjunto de validação
Modificando um pouco o procedimento descrito acima, ao invés de se ter dois conjuntos, dividimos os dados em três conjuntos disjuntos: treinamento, validação e teste. O objetivo do conjunto de validação é auxiliar o treinamento da máquina, buscando os melhores parâmetros, similar ao procedimento acima, mas, deixando o conjunto de teste fora do processo. Esse parece ser um procedimento mais confiável, pois, o conjunto de teste, no qual o modelo será avaliado, está, de fato, ausente do processo de treinamento. Perceba que o procedimento de ajuste dos parâmetros pode se repetir diversas vezes, mas o conjunto de validação é o mesmo. Assim, após várias tentativas, um conjunto de parâmetros que satisfaça a métrica usada será encontrado, porém, esse modelo estará sobreajustado ao conjunto de validação.






 Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links:
Na primeira forma, handcrafted features, um conjunto de características é recomendado por um especialista, com a ajuda de um cientista de dados, e esse processo é chamado de feature engineering. Tal processo é mostrado no caminho superior da figura acima, no qual, o trabalho do especialista é definir as características (e/ou algoritmos extratores de características), que serão usadas para representar uma árvore. Após essa definição, um modelo é treinado, com o intuito de rotular como “árvore”, toda imagem de árvore que for dada como entrada ao sistema. Vale salientar, que se poucos especialistas estiverem disponíveis no mercado, o custo de seus serviços será alto. Todavia, mesmo se os especialistas estiverem disponíveis, a tarefa é inerentemente difícil. Não é incomum que especialistas discordem (links: 
